- 通过拟合整个奖励分布进行强化学习
- 变分序列级软策略优化

1. Motivation
1.1. RL训练中的分布偏移问题
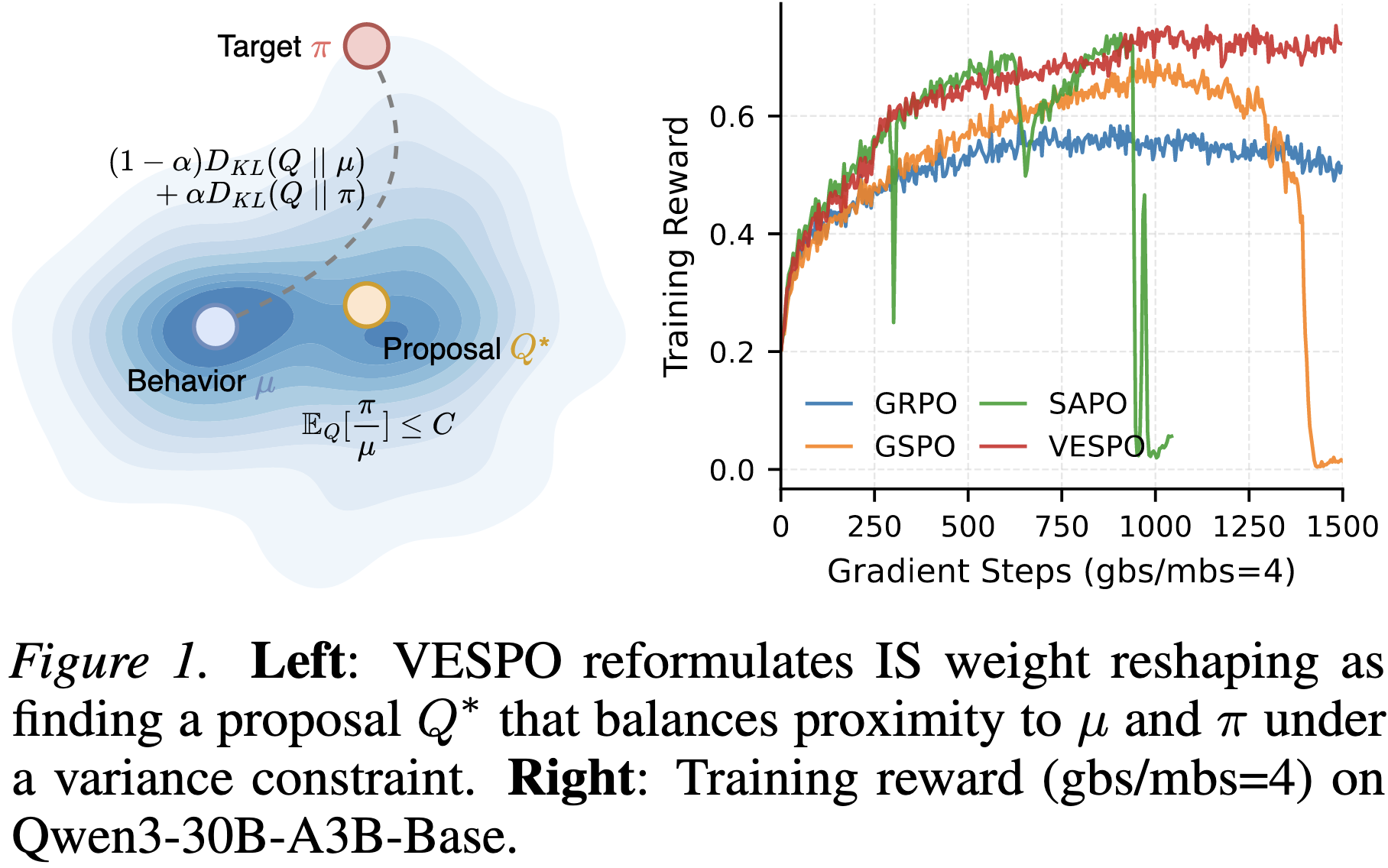
在实际的RL训练流水线中,off-policy因素是不可避免的,主要有三个方面的原因:
- mini-batch更新导致的策略过时 (policy staleness):为了提高吞吐量,系统通常在rollout阶段生成
batch_size条数据,但在策略梯度更新时,以mini_batch_size条数据为单位进行更新。由于推理阶段的开销远小于训练阶段,因此往往batch_size会大于mini_batch_size。这样一来,对于第一个以后的mini-batch,其reference policy已经过时,导致行为策略 (behavior policy, $\mu$) 与目标策略 (target policy, $\pi_{\theta}$) 不一致。 - 异步训练系统 (asynchronous training):在一些大规模异步系统中,数据rollout与模型训练完全解耦,导致 用于rollout的模型可能大幅滞后于当前训练的模型。
- 训练-推理引擎不匹配 (training-inference mismatch):推理阶段常使用vLLM/SGLang等引擎,而训练阶段则使用Megatron/FSDP。由于浮点数精度、归约顺序或MoE路由实现的细微差异,即使参数相同,输出分布也存在偏差。
1.2. 重要性采样
在策略梯度算法中,我们希望最大化轨迹 $\tau=(y_1,\dots,y_T)$ 的期望奖励:
\[\begin{equation} \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}\left[R(\tau)\right] \end{equation}\]由于我们很难对 $\pi_{\theta}$ 求期望,因此一般会通过引入一个重要性采样 (Importance Sampling, IS) 权重来转为对行为分布 $\mu$ 求期望。
此时,策略梯度为:
\[\begin{equation} \nabla_{\theta}\mathcal{J}(\theta)= \mathbb{E}_{\tau\sim\mu}\left[W(\tau)\cdot R(\tau)\cdot \nabla_{\theta}\log\pi_{\theta}(\tau)\right] \end{equation}\]其中,重要性权重为:
\[\begin{equation} W(\tau)=\frac{\pi_{\theta}(\tau)}{\mu(\tau)} \label{eq:std-is} \end{equation}\]这里的重要性权重可以看作一个梯度的缩放因子,它决定了每一个样本对于最终参数更新的贡献程度。
更一般的,任何对重要性权重的修改都可以看作是定义了一个塑形函数 $\phi(W(\tau))$ 对梯度进行塑形 (reshaping):
\[\begin{equation} \nabla_{\theta}\widetilde{\mathcal{J}}(\theta)= \mathbb{E}_{\tau\sim\mu}\left[\phi(W(\tau))\cdot R(\tau)\cdot \nabla_{\theta}\log\pi_{\theta}(\tau)\right] \label{eq:reshape-grad} \end{equation}\]1.3. 序列级IS的方差问题
一种最常见的IS方法是序列级IS (Sequence-Level IS),即对轨迹 $\tau$ 中的每一个token $y_t$ 计算一个重要性比率 (importance ratio) $\rho_t$,并【累乘】作为整条轨迹的重要性权重 $W(\tau)$:
\[\begin{equation} W(\tau)=\prod_{t=1}^T\rho_t \end{equation}\]其中,重要性比率 $\rho_t$ 定义为:
\[\begin{equation} \rho_t=\frac{\pi_{\theta}(y_t\mid x,y_{\lt t})}{\mu(y_t\mid x,y_{\lt t})} \end{equation}\]而对数策略梯度则是一个【累加】:
\[\begin{equation} \nabla_{\theta}\log\pi_{\theta}(\tau) = \sum_{t=1}^T\log\pi_{\theta}(y_t\mid x,y_{\lt t}) \end{equation}\]这种【累乘-累加】的结构会导致严重的方差问题:
每个token对于梯度的贡献是通过一个全局的重要性权重 $W(\tau)$ 来缩放的,而这个权重包含了所有 $T$ 个token的累积。即使单个token的重要性比率 $\rho_t$ 很小,但是由于累乘的性质,导致最终 $W(\tau)$ 的方差非常大。因此,序列级IS几乎无法在长文本训练场景中使用。
1.2. 现有方法的局限
为了解决方差问题,现有工作提出了多种塑形函数 $\phi(W(\tau))$,下面我们介绍几个。
在 附录A 中,我们对现有方法进行了更深入的理论层面的分析,感兴趣的读者可以自行查阅。
1.2.1. PPO / GRPO: token粒度硬截断
PPO 和 GRPO 都采用了token粒度的截断机制。从梯度的视角上看,其塑形函数取决于优势项 $A$ 的符号:
\[\begin{equation} \phi(\rho_t)= \begin{cases} \rho_t& A\gt 0,\rho_t\le 1+\varepsilon\\ \rho_t& A\lt 0,\rho_t\ge 1-\varepsilon\\ 0& \text{otherwise} \end{cases} \end{equation}\]这种方法将每个token视为独立,消除了序列级IS中的【累乘】结构。因此能够一定程度上减少方差。
局限性:
- 破坏序列结构:同一条轨迹中的不同token被赋予了不同的权重 $\text{clip}(\rho_t)$。这在数学上无法对应到任何单一的序列级分布。
- 一阶近似误差:Zheng et al. 证明,这个token级IS是序列级IS的一个一阶泰勒近似。它忽略了token间的交互信息。这种方法在近似on-policy且序列较短时是可接受的,但在off-policy程度较高或长文本任务中,近似误差会显著累积。
1.2.2. GSPO: 长度归一化
GSPO 在序列粒度上操作,试图通过 $\rho_t$ 的几何平均来控制方差:
\[\begin{equation} \phi(W)=W^{1/T} =\exp\left(\frac{1}{T}\sum_{t=1}^T\log\rho_t\right) \end{equation}\]局限性:(详见 附录A.2)
- 长度偏差:在长序列训练任务上,模型的优化方向几乎都朝向行为策略 $\mu$,而丧失了向目标分布 $\pi$ 前进的动力。
- 混淆不同轨迹:如果两条轨迹长度不同但 $\rho_t$ 的平均值相同,GSPO会赋予它们相同的权重,即使它们真是的重要性权重可能相差巨大,这导致模型无法正确区分样本的重要性。
1.2.3. SAPO: 启发式软截断
SAPO 设计了一个分段函数对重要性权重 $W$ 进行软截断:
\[\begin{equation} \begin{aligned} \phi(\rho_t)&=\sigma(\alpha_t(\rho_t-1))\cdot\frac{4}{\alpha_t}\\ \alpha_t&= \begin{cases} \alpha_{\text{pos}}& A\gt 0\\ \alpha_{\text{neg}}& \text{otherwise} \end{cases} \end{aligned} \end{equation}\]虽然避免了硬截断的不可导问题,但其函数形式设计基于启发式规则,缺乏统一的理论指导,且需要手动调节多个超参数。
2. Methodology
上面的所有方法都是在启发式地设计塑形函数 $\phi$,我们如何能抛弃这种启发式方法,设计出更加有效的塑形函数?为此,作者搭建了一整套理论框架,用于设计重要性权重的塑形函数 $\phi$。
下面的内容包括三大部分。首先,2.1.节 说明了任何塑形函数 $\phi$ 都隐式地定义了一个提案分布 (proposal distribution)。然后,2.2.节 将 $\phi$ 的设计问题转换为一个在方差约束下的变分问题。最后,2.3.节 给出了这个优化问题的最优闭式解。
2.1. 从测度变换的角度看待权重塑形
标准的重要性采样 \eqref{eq:std-is} 可以看作是一个从行为分布 $\mu$ 到目标分布 $\pi$ 的测度变换 (Measure Change) $\mu\to\pi$,而任何的塑形函数 $\phi(W)$ 都可以看作从 $\mu$ 到某个隐式的提案分布 (Proposal Distribution) $Q$ 的测度变化 $\mu\to Q$。
事实上,对于任意函数 $G$,我们都有:
\[\begin{equation} \mathbb{E}_{\tau\sim\mu}\left[ \phi(W(\tau))\cdot G(\tau) \right] = Z\cdot \mathbb{E}_{\tau\sim\mu}\left[ G(\tau) \right] \end{equation}\]其中,$Z=\mathbb{E}_\mu[\phi(W)]$ 是归一化因子。
由塑形函数 $\phi(W)$ 所定义的提案分布 $Q$ 可以表示为:
\[\begin{equation} Q(\tau) = \frac{1}{Z}\mu(\tau)\cdot\phi(W(\tau)) \label{eq:implicit-proposal-distribution} \end{equation}\]可以发现,经过整形后的梯度 \eqref{eq:reshape-grad} 正好就等价于关于提案分布 $Q$ 的策略梯度(忽略归一化因子 $Z$)。
利用提案分布,我们能够重新看待各种不同的塑形函数(见 附录A)。更重要的是,我们可以通过规定 $Q$ 的某些性质,来解出满足这些性质的最优塑形函数 $\phi$,不需要再手动设计。
2.2. 变分目标:带方差约束的双重邻近性
我们希望找到一个提案分布 $Q$,使其满足所谓的双重邻近性 (Dual Proximity):
- 接近行为策略 $\mu$:这是为了保证采样效率,避免由 $\mu$ 生成的样本不在 $Q$ 的支撑集中(或概率很低),导致有效样本量不足。
- 接近目标策略 $\pi$:这是为了减少梯度估计的有偏性,使优化方向指向当前策略。
因此,我们的变分目标就定义为 $Q$ 分别与 $\mu$ 和 $\pi$ 的KL散度的加权和:
\[\begin{equation} \mathcal{J}(Q) = (1-\alpha)D_{\mathrm{KL}}(Q\|\mu) + \alpha D_{\mathrm{KL}}(Q\|\pi) \end{equation}\]仅仅让 $Q$ 满足双重邻近性是不够的,我们还需要对重要性权重 $W(\tau)$ 的方差进行约束。由于 $W(\tau)$ 的方差与其二阶矩 $\mathbb{E}[W(\tau)^2]$ 是正相关的,因此我们对二阶矩进行约束。
具体来说,由公式 \eqref{eq:implicit-proposal-distribution} 我们可以知道:
\[\begin{equation} Q(\tau)\propto \mu(\tau)\phi(W(\tau)) \end{equation}\]因此,我们有:
\[\begin{equation} \mathbb{E}_{\tau\sim Q}\left[W(\tau)\right]\propto \mathbb{E}_{\tau\sim \mu}\left[\phi(W)\cdot W\right] \end{equation}\]又由于 $\phi(W)=W$ 是一个无偏的重要性采样,因此在这个条件下,我们有
\[\begin{equation} \mathbb{E}_{\tau\sim Q}\left[W(\tau)\right]\propto \mathbb{E}_{\tau\sim \mu}\left[W^2\right] \end{equation}\]也就是说,我们可以通过控制 $\mathbb{E}_{\tau\sim Q}\left[W(\tau)\right]$ 来控制 $W$ 在分布 $\mu$ 下的方差。
综上所述,我们的变分优化目标为:
\[\begin{equation} \begin{aligned} & \min_{Q} (1 - \alpha) D_{\mathrm{KL}}(Q \| \mu) + \alpha D_{\mathrm{KL}}(Q \| \pi) \\ & \text{s.t. } \mathbb{E}_Q[W] \leq C, \quad \int Q(\tau) \mathrm{d}\tau = 1 \end{aligned} \end{equation}\]2.3. 最优闭式解
幸运的是,上面的优化问题存在闭式的最优解(证明见 附录B):
\[\begin{equation} \begin{aligned} Q(\tau) &\propto \mu(\tau)^{1-\alpha}\pi(\tau)^{\alpha}\exp(-\lambda W(\tau))\\ &= \mu(\tau)W(\tau)^{\alpha}\exp(-\lambda W(\tau)) \end{aligned} \end{equation}\]与公式 \eqref{eq:implicit-proposal-distribution} 对比,我们就能写出最优的塑形函数:
\[\begin{equation} \phi(W)=W^{\alpha}\cdot\exp(-\lambda W) \end{equation}\]该核函数由两部分组成:
- 幂次项 $W^{\alpha}$:根据 $\alpha$ 的取值,在 $\mu$ 和 $\pi$ 之间进行插值。这保留了样本区分度,给高似然比的样本更高权重。
- 指数项 $\exp(-\lambda W)$:这是软抑制 (Soft Suppression) 的核心。当 $W$ 过大时,指数项衰减速度快于幂次项增长,从而平滑地压制了极端权重,防止方差爆炸。
此外,这个塑形函数处处光滑可微,避免了硬截断的不连续性。
2.4. 算法实现细节
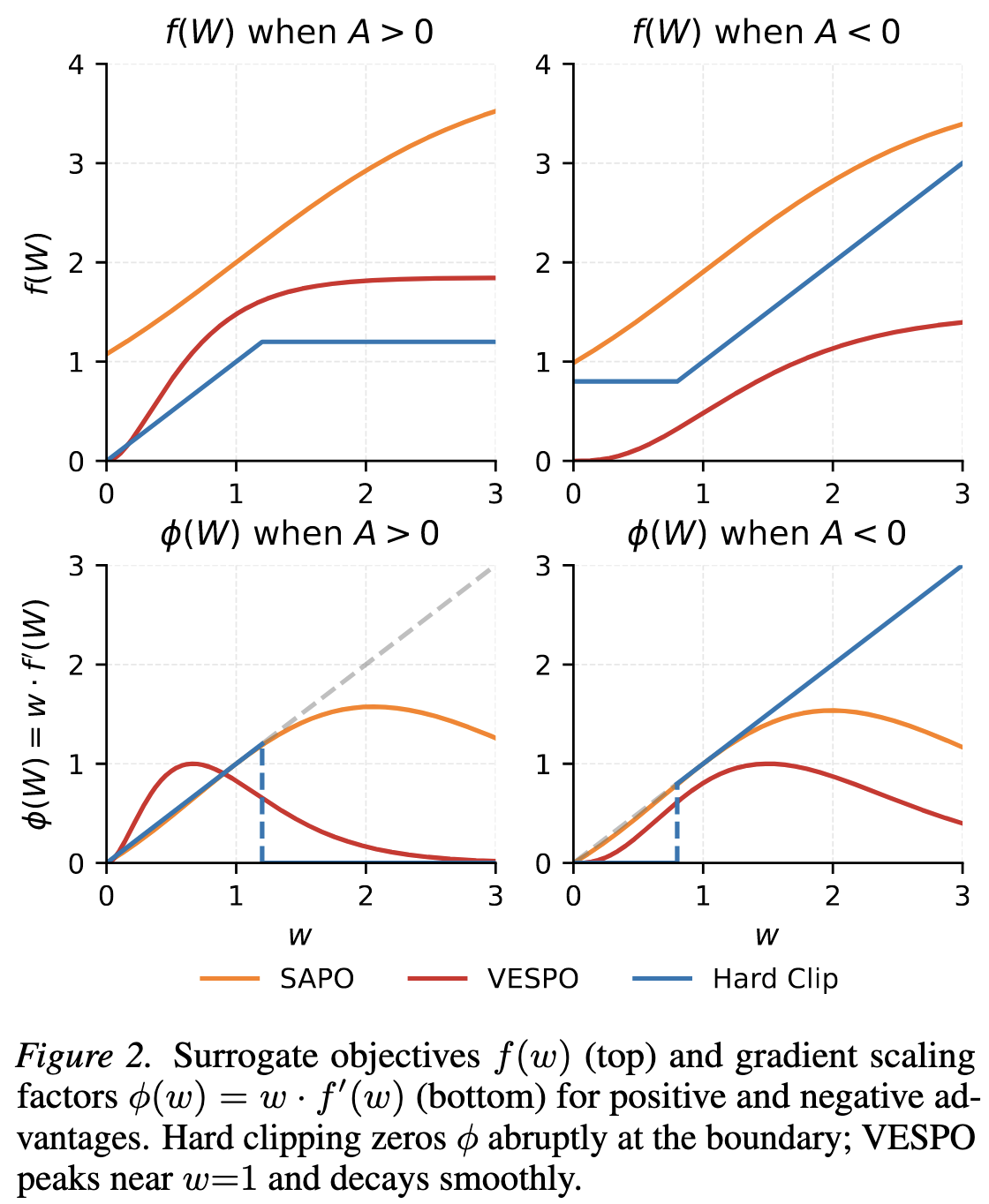
在实际应用中,为了数值稳定性和对齐on-policy行为,VESPO进行了一些工程上的调整。
2.4.1. 移位与归一化
为了保证on-policy样本 ($W=1$) 的权重为1,且梯度更新幅度与标准方法一致,作者使用了移位形式:
\[\begin{equation} \phi(W)=W^{c_1}\exp(c_2(1-W)) \end{equation}\]这样一来,满足 $\phi(1)=1$。
2.4.2. 非对称超参数
Tang et al. 指出,正优势和负优势的样本在训练中的动力学特性不同:
- 对于 $A\lt 0$ 的样本 ($W\lt 1$),如果重要性采样权重过大,会导致模型过度惩罚该样本,甚至引起长度坍塌。因此需要更强的抑制。
- 对于 $A\gt 0$ 的样本 ($W\gt 1$),则需要适度保留梯度信号以进行学习。
为此,作者为正负优势样本使用两套不同的超参数:
- 正优势样本:$(c_1,c_2)=(2.0,3,0)$
- 负优势样本:$(c_1,c_2)=(3.0,2,0)$
2.4.3. 对数空间运算
为了防止连乘、累加等操作导致数值溢出,VESPO全程在log空间中进行计算:
-
计算序列级重要性权重
\[\begin{equation} \log W=\sum_{t=1}^T(\log\pi_{\theta}(y_t\mid x,y_{\lt t})-\log\mu(y_t\mid x,y_{\lt t})) \end{equation}\] -
计算塑形后的重要性权重
\[\begin{equation} \log\phi(W)=c_1\log W+c_2(1-\exp(\log W)) \end{equation}\] -
计算梯度
\[\begin{equation} \nabla_{\theta}\mathcal{J}_{\text{VESPO}} = \mathbb{E}_{\tau\sim \mu}\left[\exp(\log(\phi(W)))\nabla_{\theta}\log\pi_{\theta}(\tau)\right] \end{equation}\]
2.4.4. 算法伪代码
def compute_policy_loss_vespo(log_pi, log_ref, advantages, mask, c_pos, c_neg):
# 1. 计算序列级重要性权重 (无长度归一化)
log_ratio = log_pi - log_ref
seq_log_w = (log_ratio * mask).sum(dim=-1)
W = exp(seq_log_w)
# 2. 非对称超参
c1 = where(advantages >= 0, c_pos[0], c_neg[0])
c2 = where(advantages < 0, c_pos[1], c_neg[1])
# 3. 计算 VESPO Kernel
# phi(W) = W^c1 * exp(c2 * (1-W))
# log_phi = c1 * log(W) + c2 * (1 - W)
log_phi = c1 * seq_log_w + c2 * (1 - W)
# 梯度截断,只用于 Scaling
phi = exp(log_phi).detach()
# 4. 策略梯度 Loss
# 注意:这里 phi 作为系数,advantages 也是系数
loss = -phi * advantages * log_pi.sum(dim=-1)
return loss.mean()
3. Experiments
3.1. Benchmark表现
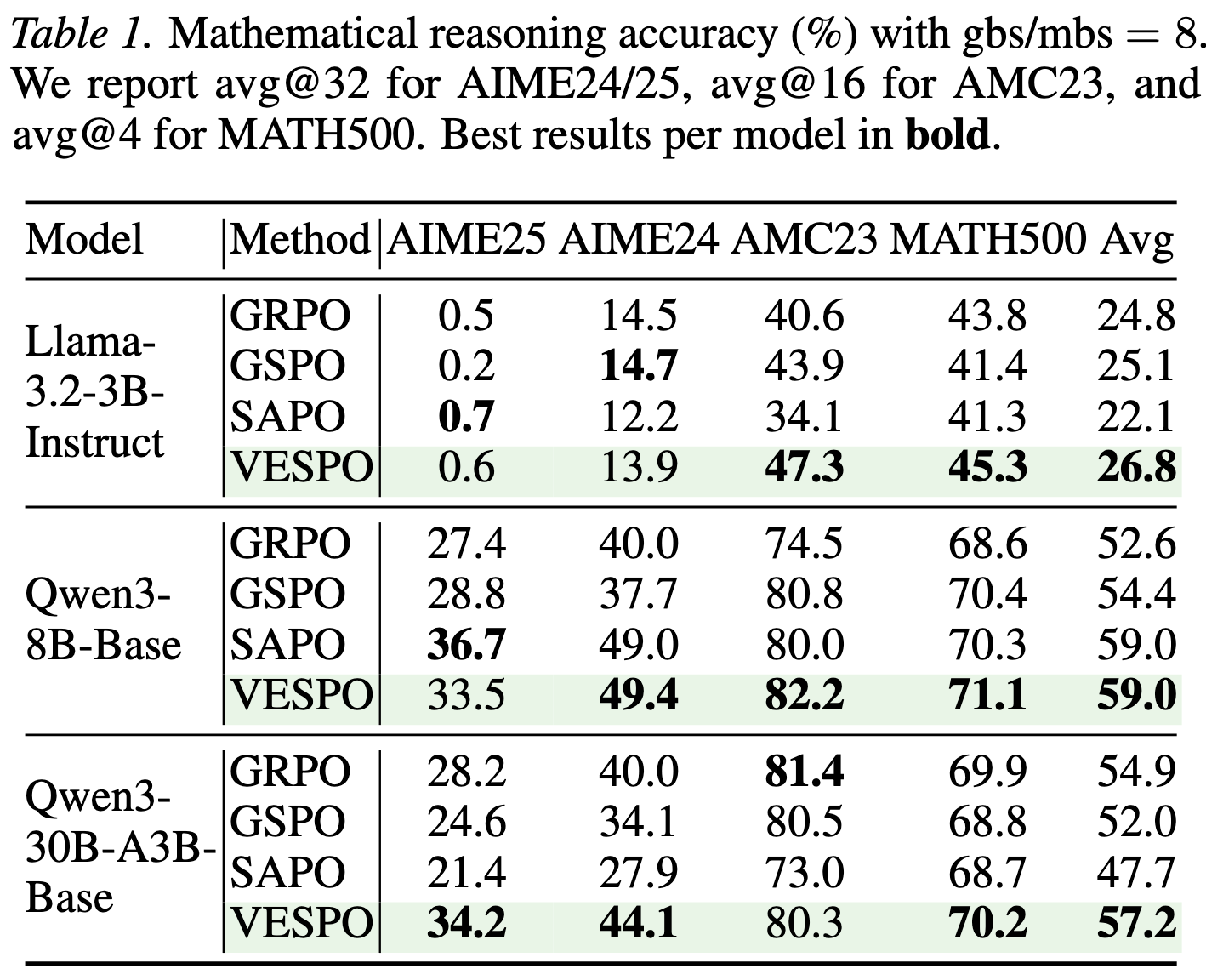
论文在多个数学推理基准 (AIME 2024/2025, AMC 2023, MATH-500) 上评估了 VESPO,使用了 Llama-3.2-3B、Qwen3-8B 和 Qwen3-30B-A3B (MoE) 模型。
3.2. 对策略过时的鲁棒性
为了模拟策略过时,实验按不同比例设置 batch_size (gbs) 与 mini_batch_size (mbs)。$N=\text{gbs}/\text{mbs}$ 越大,说明后续mini-batch更新时的过时程度越严重。
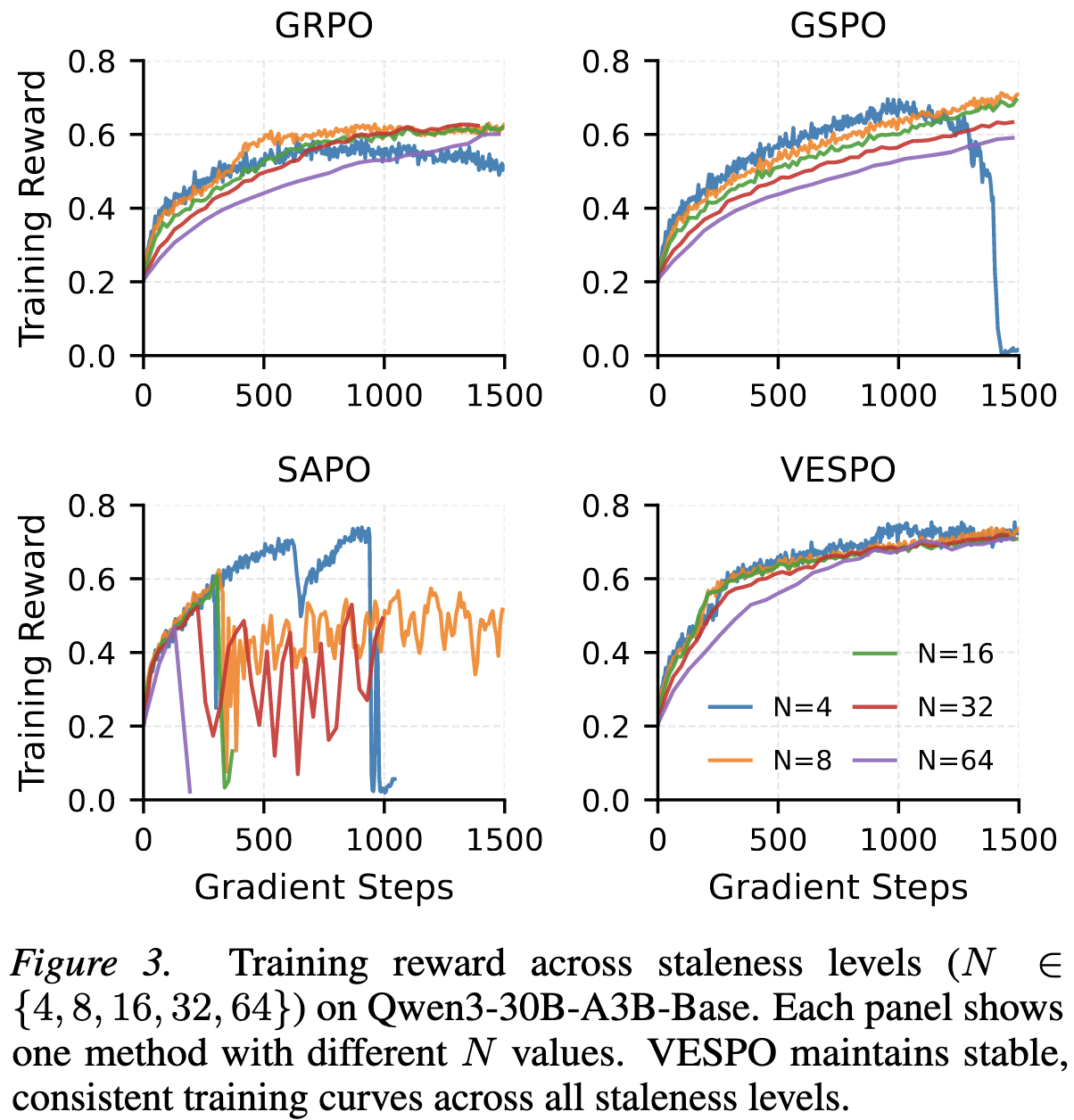
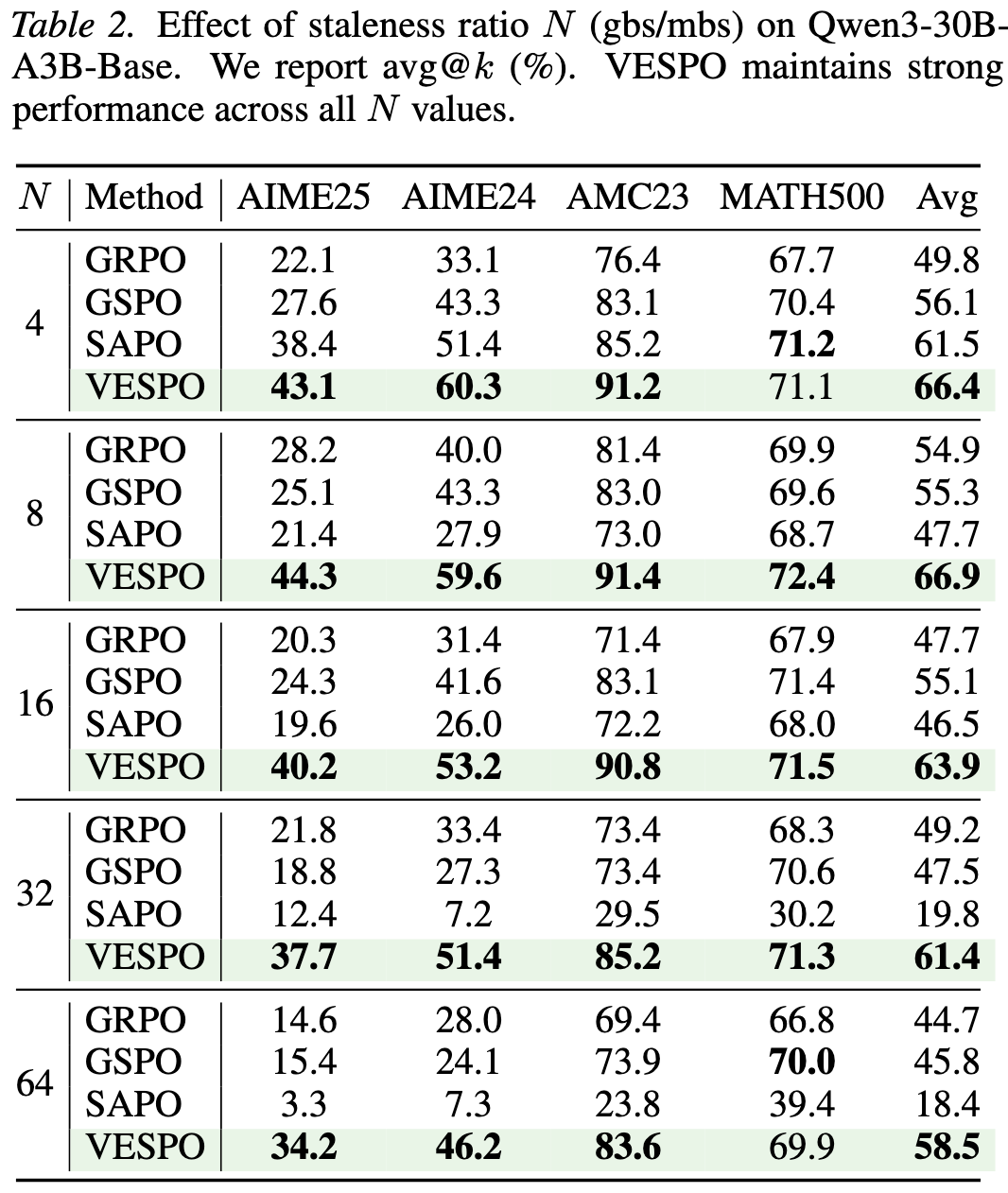
- GRPO:在 $N=4$ 时表现尚可,但随 $N$ 增加,性能迅速饱和并下降。
- GSPO:对 $N$ 非常敏感,在 $N=4$ 时出现训练坍塌(reward变为零)。
- SAPO:在 $N\ge 8$ 时训练完全崩溃。
- VESPO:在 $N=4$ 到 $N=64$ 的范围内,训练曲线几乎重合,表现出极强的鲁棒性,且最终的reward显著高于其他方法。
3.3. 全异步训练
作者全异步训练框架下测试了VESPO的鲁棒性。
全异步训练是指rollout和training节点分别运行在不同的集群上,每个trainer节点在本地更新4次之后将参数合并到rollout引擎上(类比 $N=4$)
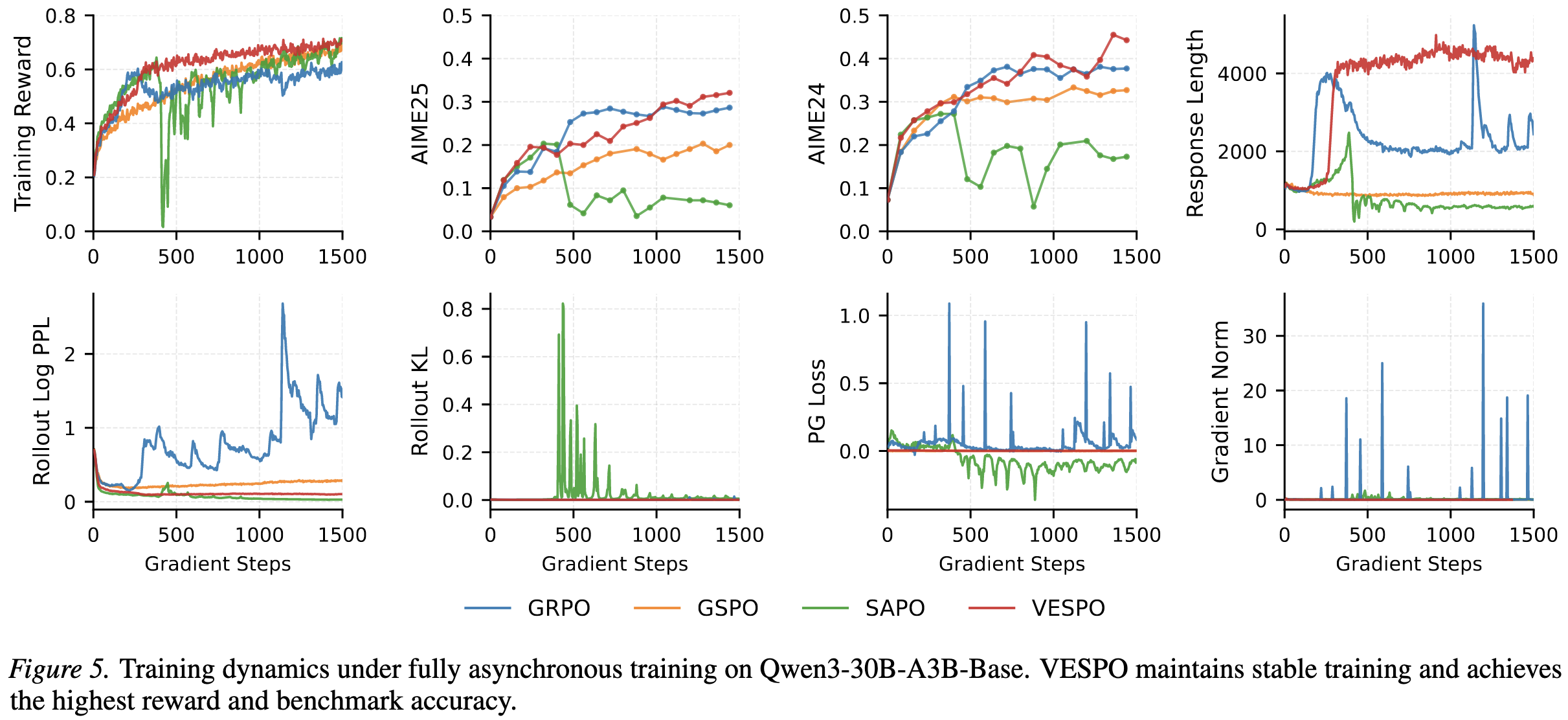
- GRPO:极不稳定,KL散度和梯度范数频繁出现尖峰,响应长度剧烈震荡。
- SAPO:在早期就坍塌。
- VESPO:保持了低且稳定的KL散度、梯度范数和entropy,最终实现了最高的训练reward。
3.4. 训练-推理不匹配问题
MoE模型由于路由决策的非确定性,受训练-推理引擎不匹配的影响最大。
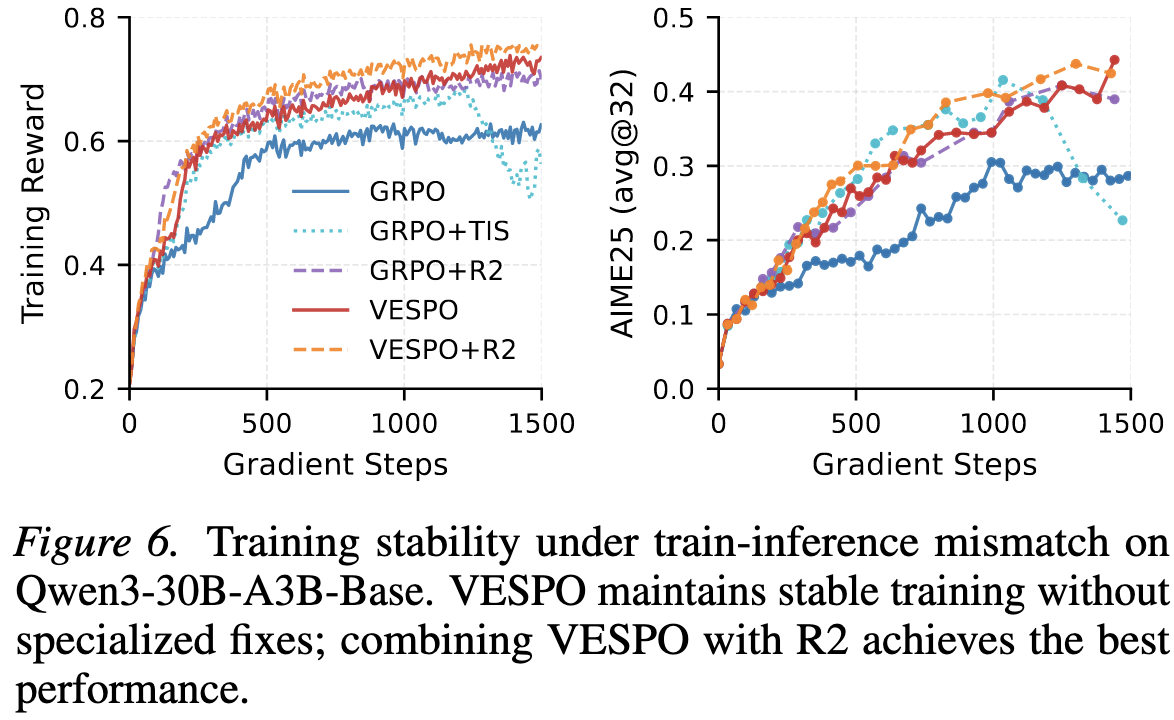
- GRPO:在MoE模型上训练时,reward 难以提升,主要受到引擎不匹配的影响。
- VESPO:即便不使用专门的工程手段,VESPO仅凭算法本身的软抑制能力,就能达到与GRPO + Routing Replay 相当的稳定性。
- VESPO + Routing Replay 能进一步提升上限,在 Qwen3-30B-A3B 上取得了最佳结果。
3.5. 长度归一化的危害
VESPO的一大亮点是:在序列粒度进行重要性采样,但无需像GSPO那样对长度进行任何归一化。
为此,作者设计了两个变体,分别用 $1/\sqrt{T}$ 和 $1/T$ 对序列级重要性权重进行归一化。
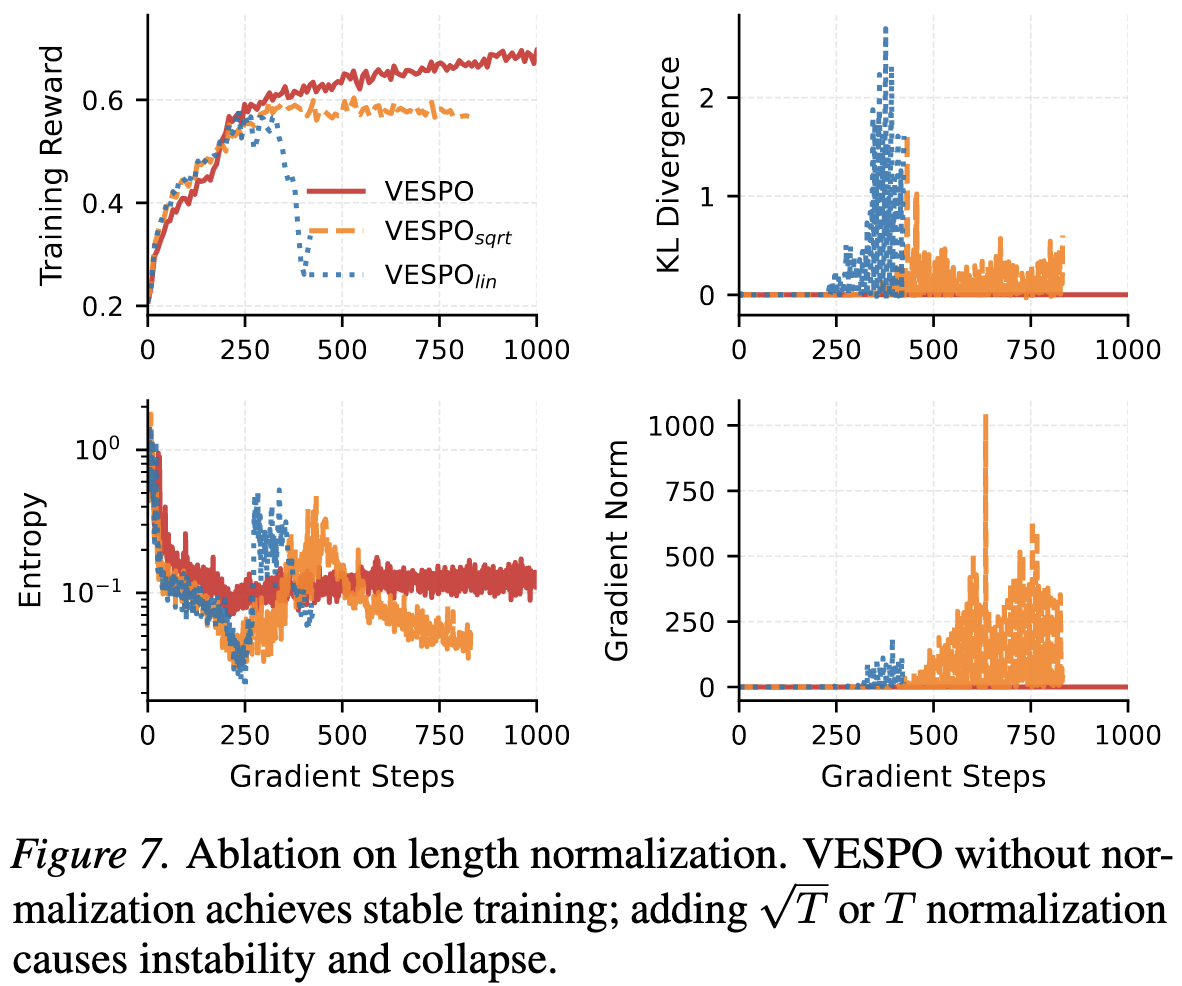
结果显示,引入长度归一化(特别是线性归一化)直接导致了训练的不稳定和崩溃。
作者分析,原因可能在于长度归一化使得长序列的权重被过度放大(因为分母 $T$ 变大,导致权重趋向于1,难以被抑制),从而使模型偏向生成更长的序列,最终导致OOM或崩溃。
4. Discussion
4.1. 为什么VESPO比token粒度截断好?
核心在于信用分配 (Credit Assignment) 的准确性。
对于一道数学题,如果是中间某个步骤错了导致最终答案错误:
- token 级方法(如 GRPO)可能会通过截断某些token的梯度来修正更新量,但这破坏了序列的整体逻辑链。
- VESPO则是从整条序列的维度,通过权重调整该条数据对梯度的贡献。
如果一条数据严重off-policy(权重极大或极小),VESPO会整体降低其权重,而不是扭曲其内部结构。
4.2. 为什么VESPO不需要长度归一化?
GSPO中引入长度归一化是因为 $W=\prod\rho$ 的方差太大。
VESPO 通过指数项 $\exp(-\lambda W)$ 提供了极强的尾部抑制能力。无论序列多长,只要 $W$ 变得过大,指数项就会将其压制回来。
这种机制比硬性的长度除法更符合统计学规律,因为它保留了 $W$ 在序列间的相对大小关系(保序性,monotonicity),只是压缩了数值范围。
4.3. 与 PPO 的关系
PPO的clip操作本质上是一种Trust Region的近似实现。
VESPO可以被视为一种在序列级别上的、软性的Trust Region方法:它不强制将更新限制在某个邻域内,而是通过降低远离 $\mu$ 的样本的权重来实现类似效果。
Reference
[1] 小红书提出 VESPO 变分序列级软策略优化,从测度变换视角重构重要性采样
Appendix
A. 从提案分布的角度看现有方法
我们在测度变换的框架下,来重新看待现有各种塑形函数所定义的提案分布 $Q$。
A.1. PPO / GRPO: token粒度硬截断
PPO和GRPO对每个token分别截断,并不考虑其在序列中的位置。
其梯度估计为:
\[\begin{equation} \nabla_{\theta}\mathcal{J}_{\text{token}} = \sum_{t=1}^T \mathbb{E}_{\tau\sim\mu}\left[ \phi(\rho_t)\cdot A(\tau)\cdot \nabla_{\theta}\log \pi(y_t\mid x,y_{\lt t}) \right] \end{equation}\]其中,塑形函数
\[\begin{equation} \phi(\rho_t)= \begin{cases} \rho_t& A\gt 0,\rho_t\le 1+\varepsilon\\ \rho_t& A\lt 0,\rho_t\ge 1-\varepsilon\\ 0& \text{otherwise} \end{cases} \end{equation}\]不同于序列级IS \eqref{eq:reshape-grad} 会为所有token赋予相同的权重 $\phi(W)$,token粒度的IS为同一条轨迹中不同的token被赋予不同的权重 $\phi(\rho_t)$。
因此,这种重要性采样方式并不能定义任何的提案分布 $Q$,因为提案分布要求同一条轨迹中的所有token有着相同的重要性系数。这种token粒度的加权方式破坏了序列级信用分配的连贯性,导致同一轨迹中共享相同最终结果的token接收到了不一致的梯度信号。”
此外,Zheng et al. 证明,这个token级IS是序列级IS的一个一阶泰勒近似。
考虑不进行截断的情况,即 $\phi(\rho_t)=\rho_t, \phi(W)=W$,序列级IS的梯度估计为:
\[\begin{equation} \begin{aligned} \nabla_{\theta}\mathcal{J}_{\text{seq}} &= \mathbb{E}_{\tau\sim\mu}\left[ W\cdot \sum_{t=1}^T \nabla_{\theta}\log \pi(y_t) \right] \end{aligned} \end{equation}\]在近似on-policy的情况下(即 $\rho_s\approx 1$),我们对 $W$ 进行一阶泰勒近似:
\[\begin{equation} \begin{aligned} W &=\prod_{s=1}^T\rho_s\\ &= 1+\sum_{s=1}^T(\rho_s-1)+\sum_{s'\lt s}(\rho_s-1)(\rho_{s'}-1)+\cdots\\ &\approx 1+\sum_{s=1}^T(\rho_s-1) \end{aligned} \end{equation}\]代入梯度估计中得:
\[\begin{equation} \begin{aligned} \nabla_{\theta}\mathcal{J}_{\text{seq}} &= \mathbb{E}_{\tau\sim\mu}\left[ \left( 1+\sum_{s=1}^T(\rho_s-1) \right) \sum_{t=1}^T \nabla_{\theta}\log \pi(y_t) \right]\\ &= \underbrace{\mathbb{E}_{\tau\sim\mu}\left[ \sum_{t=1}^T \nabla_{\theta}\log \pi(y_t) \right]}_{\text{策略梯度}} + \underbrace{\sum_{s,t} \mathbb{E}_{\tau\sim\mu}\left[ (\rho_s-1) \nabla_{\theta}\log \pi(y_t) \right]}_{\text{一阶IS修正}} \end{aligned} \label{eq:seq-grad} \end{equation}\]同时,token级的梯度估计为:
\[\begin{equation} \begin{aligned} \nabla_{\theta}\mathcal{J}_{\text{token}} &= \sum_{t=1}^T \mathbb{E}_{\tau\sim\mu}\left[ \rho_t\cdot \nabla_{\theta}\log \pi(y_t) \right]\\ &= \sum_{t=1}^T \mathbb{E}_{\tau\sim\mu}\left[ (1+\rho_t-1)\cdot \nabla_{\theta}\log \pi(y_t) \right]\\ &= \mathbb{E}_{\tau\sim\mu}\left[ \sum_{t=1}^T \nabla_{\theta}\log \pi(y_t) \right] + \sum_{t} \mathbb{E}_{\tau\sim\mu}\left[ (\rho_t-1) \nabla_{\theta}\log \pi(y_t) \right] \end{aligned} \label{eq:token-grad} \end{equation}\]对比 \eqref{eq:seq-grad} 和 \eqref{eq:token-grad},我们可以发现,token级IS \eqref{eq:token-grad} 仅保留了一阶IS修正中的对角线项 ($s=t$),忽略了token之间的交互项 $(s\neq t)$。
token级IS的近似误差为:
\[\begin{equation} \nabla_{\theta}\mathcal{J}_{\text{seq}}-\nabla_{\theta}\mathcal{J}_{\text{token}} \approx \sum_{s\neq t} \mathbb{E}_{\tau\sim\mu}\left[ (\rho_s-1) \nabla_{\theta}\log \pi(y_t) \right] + O((\rho-1)^2) \end{equation}\]这说明,改变某个位置的token $y_s$ 会对其他位置的token $y_t$ 的梯度产生影响,而token粒度的IS忽略了这一点。
因此,只有在某些条件下,token级IS才比较可用:
- 几乎on-policy:几乎所有token的 $\rho_t\approx 1$,此时高阶项和交叉项几乎可以被忽略
- 序列长度较短:序列长度较短时,交叉项较少,因此累积误差较小
A.2. GSPO: 长度归一化
GSPO使用几何平均作为序列级IS:$\phi(W)=W^{1/T}$,它对应的提案分布为:
\[\begin{equation} Q_{\text{GSPO}}(\tau) \propto \mu(\tau)^{1-1/T}\cdot\pi(\tau)^{1/T} \end{equation}\]当 $T\to\infty$ 时,$Q\to\mu$。此时重要性权重 $W\to\exp\left(\mathbb{E}[\log\rho_t]\right)$,与轨迹 $\tau$ 完全无关。
这就导致了两个严重的问题:
- 优化信号衰减 (Signal dissipation):所有轨迹的重要性系数都是一样的,失去了区分不同轨迹的能力。
- 混淆不同轨迹 (Conflation of distinct sequences):两条不同长度的序列如果有着相同的token特征,它们会被赋予相同的重要性系数。下面的 Proposition A.2.1. 说明了这一点。
Proposition A.2.1. (长度归一化导致的混淆)
考虑两个序列 $\tau_1$ 和 $\tau_2$,它们有着不同的长度 $T_1\neq T_2$,但只要满足:
\[\begin{equation} \overline{r}=\frac{\log W_1}{T_1} =\frac{\log W_2}{T_2} \end{equation}\]那么,GSPO为它们赋予的重要性权重是相同的:
\[\begin{equation} \log \phi_{\text{GSPO}}(\tau_1) =\log \phi_{\text{GSPO}}(\tau_2) =\overline{r} \end{equation}\]但它们真实的重要性权重明显是不同的:
\[\begin{equation} \begin{aligned} W_1&=\exp(T_1\overline{r})\\ W_2&=\exp(T_2\overline{r}) \end{aligned} \end{equation}\]B. 闭式解的证明
下面我们证明VESPO的变分优化问题:
\[\begin{equation} \begin{aligned} & \min_{Q} (1 - \alpha) D_{\mathrm{KL}}(Q \| \mu) + \alpha D_{\mathrm{KL}}(Q \| \pi) \\ & \text{s.t. } \mathbb{E}_Q[W] \leq C, \quad \int Q(\tau) \mathrm{d}\tau = 1 \end{aligned} \end{equation}\]的最优解为
\[\begin{equation} Q^{\ast}(\tau) \propto\mu(\tau)^{1-\alpha}\pi(\tau)^{\alpha}\exp(-\lambda W(\tau))\\ \end{equation}\]其中 $\lambda\ge 0$ 是方差约束对应的拉格朗日乘子。
考虑拉格朗日方程:
\[\begin{equation} \begin{aligned} \mathcal{L}(Q;\lambda,\gamma) &= (1 - \alpha) D_{\mathrm{KL}}(Q \| \mu) + \alpha D_{\mathrm{KL}}(Q \| \pi)\\ &\quad +\lambda\left(\mathbb{E}_Q[W]-C\right)+\gamma\left(\int Q(\tau) \mathrm{d}\tau-1\right) \end{aligned} \end{equation}\]展开KL散度得:
\[\begin{equation} \begin{aligned} \mathcal{L}(Q;\lambda,\gamma) &= (1-\alpha) \int Q(\tau)\log \frac{Q(\tau)}{\mu(\tau)}\mathrm{d}\tau +\alpha \int Q(\tau)\log \frac{Q(\tau)}{\pi(\tau)}\mathrm{d}\tau\\ &\quad +\lambda \left( \int Q(\tau)W(\tau)\mathrm{d}\tau-C \right) +\gamma\left(\int Q(\tau)\mathrm{d}\tau-1\right)\\ &= \int Q(\tau) \left[ \log Q(\tau) - (1-\alpha)\log\mu(\tau) - \alpha\log\pi(\tau)+\lambda W(\tau)+\gamma \right]\mathrm{d}\tau\\ &\quad -\lambda C-\gamma \end{aligned} \end{equation}\]令拉格朗日函数关于 $Q$ 的函数导数为0得:
\[\begin{equation} \begin{aligned} \frac{\delta \mathcal{L}}{\delta Q} &=\log Q(\tau) +1-(1-\alpha)\log\mu(\tau) - \alpha\log\pi(\tau)+\lambda W(\tau)+\gamma\\ &=0 \end{aligned} \end{equation}\]解得:
\[\begin{equation} \begin{aligned} \log Q^{\ast}(\tau)&=(1-\alpha)\log\mu(\tau) + \alpha\log\pi(\tau)-\lambda W(\tau)+\text{const}\\ Q^{\ast}(\tau)&\propto \mu(\tau)^{1-\alpha}\pi(\tau)^{\alpha}\exp(-\lambda W(\tau))\\ \end{aligned} \end{equation}\]得证。