一、DDPM
下面我们利用高斯过程的理论模型,来介绍一下大家耳熟能详的 DDPM (Denoising Diffusion Probabilistic Model)。
前面已经有一篇博客 生成模型 (1.3):Denoising Diffusion Probabilistic Model 详细介绍了DDPM,那里的推导更加的严谨和完整,有兴趣的读者可以自行查看。
1.1. DDPM概览
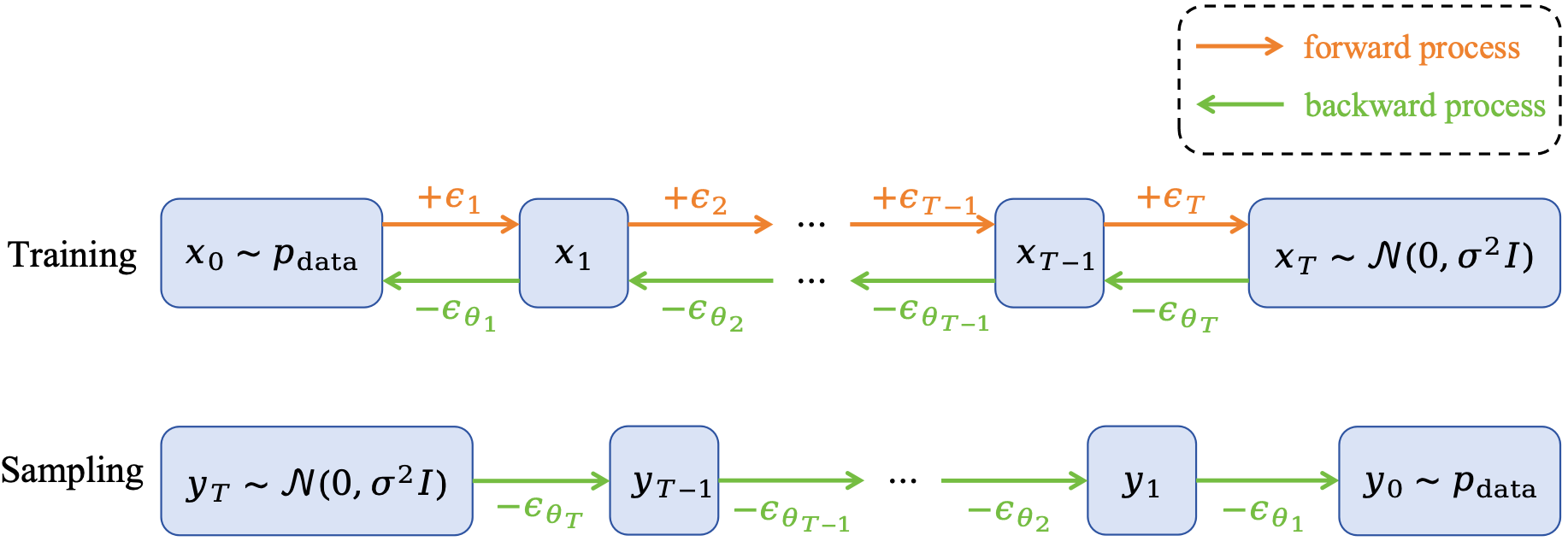
当前所有的生成式模型,实际上都是一个随机数生成器,它在某个分布上进行采样 (sampling),以此来生成一个随机数。然而,目标分布通常非常复杂且高维,直接对其进行采样是非常困难的。因此,一个很常见的想法是我们从一个简单的分布 (如高斯分布) 进行采样,然后通过一些变换,将其映射到数据分布上。
因此,生成模型需要学习的并不是目标分布本身,而是【从高斯分布映射到目标分布的方法】。
Fig.1 中展示了DDPM的理论框架,其DDPM的核心思想是:
- 在训练阶段,我们将目标分布逐步破坏为一个高斯分布(前向过程),通过学习前向过程的逆过程,来从高斯分布恢复出目标分布(后向过程)。
- 在采样阶段,我们从高斯分布中采样一个随机数,并利用学到的逆过程,逐步恢复出目标分布。
在前向过程中,每一步所加的噪声 $\varepsilon_t$ 都是一个随机变量。当加噪步骤 $T$ 足够大时,我们希望样本点 $x_T$ 已经被破坏为一个纯高斯噪声。在后向过程中,我们需要用一个神经网络 $\varepsilon_{\theta_t}$ 来预测当前时间步 $t$ 上的噪声 $\varepsilon_t$,并利用这个预测值来恢复出上一步的样本点 $x_{t-1}$。
1.2. 前向过程
在前向过程中,我们需要控制每一步所加噪声的分布,让我们能够更好地控制样本点的变化趋势。
具体来说,前向过程的递推表达式如下:
\[\begin{equation} x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\varepsilon_t \label{eq:forward-process-1} \end{equation}\]其中,$\varepsilon_t\sim\mathcal{N}(0,I)$ 是标准高斯噪声,$\alpha_t\in(0,1]$ 是噪声强度参数。
公式 \eqref{eq:forward-process-1} 表明,前向过程的每一步是上一步的数据点和标准高斯噪声的一个线性组合,并通过超参数 $\alpha_t$ 来控制二者的比例。
这个表达式的形式是经过精心设计的,它使得我们可以用优美的形式来直接写出前向过程的第 $t$ 步的样本点 $x_t$,而不需要逐步计算。具体来说:
\[\begin{equation} \begin{aligned} x_t &= \sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\varepsilon_t\\ &= \sqrt{\alpha_t} \left(\sqrt{\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}\varepsilon_{t-1}\right) +\sqrt{1-\alpha_t}\varepsilon_t\\ &= \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} +\sqrt{\alpha_t}\sqrt{1-\alpha_{t-1}}\varepsilon_{t-1} +\sqrt{1-\alpha_t}\varepsilon_t\\ \end{aligned} \end{equation}\]由于 $\varepsilon_{t-1},\varepsilon_{t}\sim\mathcal{N}(0,I)$,因此,后面的噪声项的方差为 $\alpha_t(1-\alpha_{t-1})+1-\alpha_t=1-\alpha_t\alpha_{t-1}$,均值为0。
因此,
\[\begin{equation} \begin{aligned} x_t &= \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} +\sqrt{1-\alpha_t\alpha_{t-1}}\varepsilon_{t-1}\\ &=\cdots\\ &=\sqrt{\prod_{k=1}^t\alpha_k}\cdot x_0 +\sqrt{1-\prod_{k=1}^t\alpha_k}\cdot\varepsilon\\ \end{aligned} \end{equation}\]我们记 $\overline{\alpha_t}:= \prod_{k=1}^t \alpha_k$,则:
\[\begin{equation} x_t=\sqrt{\overline{\alpha}_t}\cdot x_0 +\sqrt{1-\overline{\alpha}_t}\cdot\varepsilon \label{eq:forward-process-2} \end{equation}\]公式 \eqref{eq:forward-process-2} 就是前向过程中任意时间步 $t$ 上的样本点 $x_t$ 的表达式。
1.3. 后向过程
在后向过程中,我们实际上希望对后验分布 $p(x_{t-1}\mid x_t,x_0)$ 进行建模,这也被称为后向过程的转移核 (transition kernel)。
Note:这里实际上已经用到了条件化技巧,即只考虑初始条件为 $x_0$ 时的转移核。
更多关于条件化技巧的内容,读者可以参考 这里。
根据贝叶斯公式,我们有:
\[\begin{equation} p(x_{t-1}\mid x_t,x_0) = p(x_t\mid x_{t-1},x_0)\cdot \frac{p(x_{t-1}\mid x_0)}{p(x_t\mid x_0)} \label{eq:posterior-kernel-1} \end{equation}\]右侧的三个分布的形式我们都是已知的。
其中,根据公式 \eqref{eq:forward-process-1},似然
\[\begin{equation} p(x_t\mid x_{t-1},x_0)\sim\mathcal{N} \left( \sqrt{\alpha_t}x_{t-1}, (1-\alpha_t)I \right) \end{equation}\]根据公式 \eqref{eq:forward-process-2},先验分布
\[\begin{equation} p(x_{t-1}\mid x_0)\sim\mathcal{N} \left( \sqrt{\overline{\alpha}_{t-1}}x_0, (1-\overline{\alpha}_{t-1})I \right) \end{equation}\]同理,证据
\[\begin{equation} p(x_t\mid x_0)\sim\mathcal{N} \left( \sqrt{\overline{\alpha}_t}x_0, (1-\overline{\alpha}_t)I \right) \end{equation}\]因此,我们可以写出转移核 \eqref{eq:posterior-kernel-1} 的形式。
由于是三个高斯分布,我们只考虑指数上方的二次型。注意我们的变量始终是 $x_{t-1}$,因此我们只关心与 $x_{t-1}$ 有关的项,$x_t$ 和 $x_0$ 都是常数,我们完全不关心。
\[\begin{equation} \begin{aligned} &\quad -\frac{1}{2}\left( \underbrace{\frac{\left(x_t-\sqrt{\alpha_t}x_{t-1}\right)^2}{1-\alpha_t}}_{\text{likelihood}} - \underbrace{\frac{\left(x_t-\sqrt{\overline{\alpha}_t}x_0\right)^2}{1-\overline{\alpha}_t}}_{\text{evidence}} + \underbrace{\frac{\left(x_{t-1}-\sqrt{\overline{\alpha}_{t-1}}x_0\right)^2}{1-\overline{\alpha}_{t-1}}}_{\text{prior}} \right)\\ &=-\frac{1}{2}\left( \frac{x_t^2-2 \sqrt{\alpha_t} x_t x_{t-1}+\alpha_t x_{t-1}^2}{1-\alpha_t} - \frac{x_t^2-2 \sqrt{\overline{\alpha}_t} x_t x_0+\overline{\alpha}_t x_0^2}{1-\overline{\alpha}_t} + \frac{x_{t-1}^2-2 \sqrt{\overline{\alpha}_{t-1}} x_{t-1} x_0+\overline{\alpha}_{t-1} x_0^2}{1-\overline{\alpha}_{t-1}} \right)\\ &=-\frac{1}{2}\left( \left( \frac{\alpha_t}{1-\alpha_t} + \frac{1}{1-\overline{\alpha}_{t-1}} \right)x_{t-1}^2 - 2x_{t-1} \left( \frac{\sqrt{\alpha_t} }{1-\alpha_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} }{1-\overline{\alpha}_{t-1}}x_0 \right) + C(x_0,x_t) \right) \end{aligned} \end{equation}\]由此,我们可以知道,后验转移核也是一个高斯分布(指数上方二次型),且其方差为:
\[\begin{equation} \begin{aligned} \sigma^2 &= \left( \frac{\alpha_t}{1-\alpha_t} + \frac{1}{1-\overline{\alpha}_{t-1}} \right)^{-1}\\ &= \left( \frac{ \alpha_t\left(1-\overline{\alpha}_{t-1}\right)+1-\alpha_t }{ \left(1-\alpha_t\right) \left(1-\overline{\alpha}_{t-1}\right) } \right)^{-1}\\ &= \left( \frac{ 1-\overline{\alpha}_t }{ \left(1-\alpha_t\right) \left(1-\overline{\alpha}_{t-1}\right) } \right)^{-1} \end{aligned} \label{eq:posterior-variance} \end{equation}\]其均值为:
\[\begin{equation} \begin{aligned} \mu &= \frac{ \frac{\sqrt{\alpha_t} }{1-\alpha_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}} }{1-\overline{\alpha}_{t-1}}x_0 }{ \frac{ 1-\overline{\alpha}_t }{ \left(1-\alpha_t\right) \left(1-\overline{\alpha}_{t-1}\right) } }\\ &= \frac{ \sqrt{\alpha_t}\left(1-\overline{\alpha}_{t-1}\right) }{ 1-\overline{\alpha}_t }x_t + \frac{ \sqrt{\overline{\alpha}_{t-1}}\left(1-\alpha_t\right) }{ 1-\overline{\alpha}_t }x_0 \end{aligned} \label{eq:posterior-mean} \end{equation}\]Note:上面的证明比较粗略,读者如果对严格的证明感兴趣,可以参考 这里。
1.4. $\varepsilon$-prediction
公式 \eqref{eq:posterior-mean} 中给出了后验转移核 $p(x_{t-1}\mid x_t,x_0)$ 的均值。然而我们发现其中包含了 $x_0$,在采样阶段,我们是不知道 $x_0$ 的,因此我们实际上需要利用神经网络 $x_{\theta}$ 来建模 $x_0$,这也被称为 $x$-prediction。
然而实际发现,$x$-prediction 的效果并不好,更好的方式是预测每一步的噪声 $\varepsilon_t$。
这是可以做到的,因为公式 \eqref{eq:forward-process-2} 已经给出了噪声 $\varepsilon$ 与 $x_0$ 和 $x_t$ 之间的关系:
\[\begin{equation} x_0=\frac{1}{\sqrt{\overline{\alpha}_t}} \left( x_t-\sqrt{1-\overline{\alpha}_t}\varepsilon \right) \end{equation}\]代入 \eqref{eq:posterior-mean},我们可以得到:
\[\begin{equation} \begin{aligned} \mu &=\frac{ \sqrt{\alpha_t}\left(1-\overline{\alpha}_{t-1}\right) }{ 1-\overline{\alpha}_t }x_t + \frac{ \sqrt{\overline{\alpha}_{t-1}}\left(1-\alpha_t\right) }{ 1-\overline{\alpha}_t } \cdot\frac{1}{\sqrt{\overline{\alpha}_t}} \left( x_t-\sqrt{1-\overline{\alpha}_t}\varepsilon \right)\\ &= \left( \frac{ \sqrt{\alpha_t}\left(1-\overline{\alpha}_{t-1}\right) }{ 1-\overline{\alpha}_t } + \frac{ \sqrt{\overline{\alpha}_{t-1}}\left(1-\alpha_t\right) }{ \left(1-\overline{\alpha}_t\right)\sqrt{\overline{\alpha}_t} } \right)x_t - \frac{ \sqrt{\overline{\alpha}_{t-1}}\left(1-\alpha_t\right) }{ \left(1-\overline{\alpha}_t\right)\sqrt{\overline{\alpha}_t} }\sqrt{1-\overline{\alpha}_t}\varepsilon\\ &= \frac{ \sqrt{\alpha_t}\sqrt{\overline{\alpha}_t}\left(1-\overline{\alpha}_{t-1}\right) - \sqrt{\overline{\alpha}_{t-1}}\left(1-\alpha_t\right) }{ \left(1-\overline{\alpha}_t\right)\sqrt{\overline{\alpha}_t} }x_t - \frac{ 1-\alpha_t }{ \sqrt{1-\overline{\alpha}_t}\sqrt{\alpha_t} }\varepsilon \\ &=\frac{1}{\sqrt{\alpha_t}}\left(x_t-\frac{1-\alpha_t}{\sqrt{1-\overline{\alpha}_t}}\varepsilon\right) \end{aligned} \end{equation}\]因此,我们使用神经网络来估计这里的噪声项 $\varepsilon$,以此来从 $x_t$ 中恢复 $x_{t-1}$。
二、线性高斯系统
下面我们来介绍线性高斯系统 (Linear Gaussian System)。
假设我们有一个系统,其中包括几个要素:
- 内在状态 $X$ (Intrinsic State),不能被直接观测到,类似于隐变量。
- 观测量 $Y$ (Observation),能够直接观测到的数据,可以在一定程度上反映系统的内在状态。
- 噪声 $\varepsilon$
我们希望通过观测量来推断系统的内在状态。最经典的建模方式是下面的线性模型:
\[\begin{equation} Y=AX+\varepsilon \end{equation}\]即内在状态经过某种过程 $A$ 后,结合噪声,变为可观测的观测量 $Y$。
同时,我们假设 $X\sim\mathcal{N}(\mu,\Sigma_X)$ 和噪声 $\varepsilon\sim\mathcal{N}(0,\Sigma_\varepsilon)$ 是相互独立的高斯随机变量。因此,整个系统被称为线性高斯系统。
根据高斯分布的线性性,我们很容易知道 $Y$ 也是一个高斯随机变量。同时,我们也可以证明 $X$ 和 $Y$ 的联合分布也是高斯分布。
事实上,我们有:
\[\begin{equation} \begin{pmatrix} X \\ Y \end{pmatrix} = \begin{pmatrix} I&0\\A&I \end{pmatrix} \begin{pmatrix} X \\ \varepsilon \end{pmatrix} \end{equation}\]由于 $X$ 和 $\varepsilon$ 是独立的高斯变量,因此 $\begin{pmatrix}X \ \varepsilon \end{pmatrix}$ 也是高斯变量。高斯分布经过线性变换仍然是高斯分布。因此 $\begin{pmatrix}X \ Y \end{pmatrix}$ 也是高斯变量。
我们希望研究的对象是 $X\mid Y$,即给定观测量 $Y$,我们希望推断出内在状态 $X$。我们已经知道,这个条件分布也是一个高斯分布,其均值和协方差矩阵分别为:
\[\begin{equation} \begin{aligned} \mathbb{E}[X\mid Y] &= \mathbb{E}[X]+\Sigma_{XY}\Sigma_{Y}^{-1}\left(Y-\mathbb{E}[Y]\right)\\ \Sigma_{X\mid Y} &= \Sigma_{X}-\Sigma_{XY}\Sigma_{Y}^{-1}\Sigma_{YX} \end{aligned} \end{equation}\]其中,$Y$ 的均值
\[\begin{equation} \begin{aligned} \mathbb{E}[Y] &=\mathbb{E}[AX+\varepsilon]\\ &= A\mathbb{E}[X] \end{aligned} \end{equation}\]$Y$ 的协方差矩阵:
\[\begin{equation} \begin{aligned} \Sigma_{Y} &= \mathbb{E}\left[ (Y-\mathbb{E}[Y]) (Y-\mathbb{E}[Y])^T \right]\\ &= \mathbb{E}\left[ (AX-A\mathbb{E}[X]+\varepsilon) (AX-A\mathbb{E}[X]+\varepsilon)^T \right]\\ &= A \mathbb{E}\left[ (X-\mathbb{E}[X]) (X-\mathbb{E}[X])^T \right] A^T + \mathbb{E}[\varepsilon\varepsilon^T]\\ &=A\Sigma_XA^T+\Sigma_\varepsilon\\ \end{aligned} \end{equation}\]互相关矩阵
\[\begin{equation} \begin{aligned} \Sigma_{XY} &= \mathbb{E}\left[ (X-\mathbb{E}[X]) (Y-\mathbb{E}[Y])^T \right]\\ &= \mathbb{E}\left[ (X-\mathbb{E}[X]) (AX+\varepsilon-A\mathbb{E}[X])^T \right]\\ &= \mathbb{E}\left[ (X-\mathbb{E}[X]) (A(X-\mathbb{E}[X]))^T \right]\\ &=\Sigma_XA^T\\ \Sigma_{YX} &=\Sigma_{XY}^T\\ &=A\Sigma_X\\ \end{aligned} \end{equation}\]全部代入得,条件分布的均值和协方差矩阵分别为:
\[\begin{equation} \begin{aligned} \mathbb{E}[X\mid Y] &= \mu+\Sigma_XA^T\left(A\Sigma_XA^T+\Sigma_\varepsilon\right)^{-1}(Y-A\mu)\\ \Sigma_{X\mid Y} &= \Sigma_X-\Sigma_XA^T\left(A\Sigma_XA^T+\Sigma_\varepsilon\right)^{-1}A\Sigma_X \end{aligned} \end{equation}\]三、高斯分布的一些运算练习
3.1. n阶矩
设 $X,Y\overset{i.i.d.}{\sim}\mathcal{N}(0,\sigma^2)$,求 $\mathbb{E}[(X+Y)^n\mid X-Y]$。
首先,我们证明 $X+Y$ 和 $X-Y$ 是独立的。事实上:
\[\begin{equation} \begin{pmatrix} X+Y \\ X-Y \end{pmatrix} = \begin{pmatrix} 1&1\\1&-1 \end{pmatrix} \begin{pmatrix} X \\ Y \end{pmatrix} \end{equation}\]根据高斯分布的线性性,这二者的联合分布为:
\[\begin{equation} \begin{pmatrix} X+Y \\ X-Y \end{pmatrix} \sim \mathcal{N}\left( 0, \begin{pmatrix} 1&1\\1&-1 \end{pmatrix}I \begin{pmatrix} 1&1\\1&-1 \end{pmatrix}^T \right) =\mathcal{N}(0,2I) \end{equation}\]其协方差矩阵是对角矩阵,因此 $X+Y$ 和 $X-Y$ 是独立的。又因为映射不改变独立性,因此 $(X+Y)^n$ 和 $X-Y$ 也是独立的。
因此,$\mathbb{E}[(X+Y)^n\mid X-Y]=\mathbb{E}[(X+Y)^n]$,其中,$X+Y\sim\mathcal{N}(0,2\sigma^2)$。
下面,我们求 $X\sim\mathcal{N}(0,\sigma^2)$ 的 $n$ 阶矩。
3.1.1. 直接积分
\[\begin{equation} \begin{aligned} \mathbb{E}\left[X^n\right] &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} x^n \exp\left(-\frac{x^2}{2\sigma^2}\right) \mathrm{d}x\\ &= -\frac{\sigma}{\sqrt{2\pi}} \int_{-\infty}^{\infty} x^{n-1} \mathrm{d}\exp\left(-\frac{x^2}{2\sigma^2}\right)\\ &= \underbrace{\left. -\frac{\sigma}{\sqrt{2\pi}} x^{n-1} \exp\left(-\frac{x^2}{2\sigma^2}\right) \right|_{-\infty}^{\infty}}_{=0} +\frac{\sigma}{\sqrt{2\pi}} \int_{-\infty}^{\infty} \exp\left(-\frac{x^2}{2\sigma^2}\right) \mathrm{d}x^{n-1}\\ &= (n-1)\sigma^2\frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} x^{n-2} \exp\left(-\frac{x^2}{2\sigma^2}\right) \mathrm{d}x\\ &= (n-1)\sigma^2\mathbb{E}\left[X^{n-2}\right]\\ &= (n-1)(n-3)\sigma^4\mathbb{E}\left[X^{n-4}\right]\\ &=\cdots\\ &= \begin{cases} 0,&n \text{ is odd}\\ \sigma^n(n-1)!!,&n \text{ is even} \end{cases} \end{aligned} \end{equation}\]3.1.2. 矩母函数
一个随机变量 $X$ 的矩母函数 (moment generating function, MGF) 定义为:
\[\begin{equation} M_X(t) = \mathbb{E}\left[ \exp(tX) \right] \end{equation}\]将矩母函数在 $t=0$ 处进行泰勒展开得:
\[\begin{equation} M_X^{(n)}(t) = \sum_{n=0}^{\infty} \frac{t^n}{n!} \mathbb{E}\left[ X^n \right] \label{eq:mgf-taylor} \end{equation}\]因此,矩母函数是求解 $n$ 阶矩的一种方便方法。
特别地,对于 $X\sim\mathcal{N}(0,\sigma^2)$,其矩母函数为:
\[\begin{equation} \begin{aligned} M_X(t) &= \mathbb{E}\left[ \exp(tX) \right]\\ &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp(tx) \exp\left(-\frac{x^2}{2\sigma^2}\right) \mathrm{d}x\\ &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp\left(tx-\frac{x^2}{2\sigma^2}\right) \mathrm{d}x\\ &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp\left( -\frac{1}{2\sigma^2} \left( x^2-2\sigma^2tx \right) \right) \mathrm{d}x\\ &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp\left( -\frac{1}{2\sigma^2} \left[ \left( x-\sigma^2t \right)^2 - \sigma^4t^2 \right] \right) \mathrm{d}x\\ &= \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp\left( -\frac{\left( x-\sigma^2t \right)^2}{2\sigma^2} +\frac{\sigma^2t^2}{2} \right) \mathrm{d}x\\ &= \exp\left(\frac{\sigma^2t^2}{2}\right) \frac{1}{\sqrt{2\pi}\sigma} \int_{-\infty}^{\infty} \exp\left( -\frac{\left( x-\sigma^2t \right)^2}{2\sigma^2} \right) \mathrm{d}x\\ &= \exp\left(\frac{\sigma^2t^2}{2}\right) \end{aligned} \label{eq:gaussian-mgf} \end{equation}\]将 \eqref{eq:gaussian-mgf} 在 $t=0$ 处展开得:
\[\begin{equation} \begin{aligned} M_X(t) &= \sum_{n=0}^{\infty} \frac{(\sigma^2t^2/2)^n}{n!}\\ &= \sum_{n=0}^{\infty} \frac{\sigma^{2n}}{2^nn!}t^{2n} \end{aligned} \label{eq:gaussian-mgf-taylor} \end{equation}\]将 \eqref{eq:gaussian-mgf-taylor} 与 \eqref{eq:mgf-taylor} 对比同次幂的系数得:
- 当 $n$ 为奇数时,系数为0,因此 $\mathbb{E}[X^n]=0$。
-
当 $n=2k$ 为偶数时,有:
\[\begin{equation} \frac{\mathbb{E}[X^{2k}]}{(2k)!} =\frac{\sigma^{2k}}{2^kk!} \end{equation}\]从而,
\[\begin{equation} \mathbb{E}[X^{2k}] =\frac{(2k)!}{2^kk!}\sigma^{2k}=\sigma^{2k}(2k-1)!! \end{equation}\]
综上所述,
\[\begin{equation} \mathbb{E}[X^n] =\begin{cases} 0,&n \text{ is odd}\\ \sigma^n(n-1)!!,&n \text{ is even} \end{cases} \end{equation}\]3.2. 三角函数
在上面的条件下,求 $\mathbb{E}[\cos(X+Y)\mid X-Y]=\mathbb{E}[\cos(X+Y)]$。
扩展到一般情况,设 $X\sim\mathcal{N}(\mu,\sigma^2)$,我们希望求 $\mathbb{E}[\cos(X)]$。
这里,我们没法像上面那样直接积分,而是要借助特征函数:
\[\begin{equation} \Phi_X(\omega) = \exp\left( j\mu\omega -\frac{1}{2}\sigma^2\omega^2 \right) \end{equation}\]根据欧拉公式:
\[\begin{equation} \begin{aligned} \mathbb{E}\left[ \cos(X) \right] &= \mathbb{E}\left[ \frac{1}{2}\left( \exp(jX)+\exp(-jX) \right) \right]\\ &= \frac{1}{2}\left(\Phi_X(1)+\Phi_X(-1)\right)\\ &= \frac{1}{2}\left( \exp\left( j\mu -\frac{1}{2}\sigma^2 \right)+ \exp\left( -j\mu -\frac{1}{2}\sigma^2 \right) \right)\\ &= \frac{1}{2} \exp\left( -\frac{1}{2}\sigma^2 \right) \left( \exp(j\mu)+\exp(-j\mu) \right)\\ &= \exp\left( -\frac{1}{2}\sigma^2 \right)\cos\mu \end{aligned} \end{equation}\]3.3. 不独立的情况
在上面的例子中,我们都不需要考虑条件 $X-Y$,这是因为 $X+Y$ 与 $X-Y$ 是独立的。但如果需要考虑条件时,计算就变得比较复杂。
在上面的条件下,我们试图求 $\mathbb{E}[(X+2Y)^2\mid X-Y]$。
此时,联合分布变为:
\[\begin{equation} \begin{pmatrix} X+2Y \\ X-Y \end{pmatrix} \sim \mathcal{N}\left( 0, \begin{pmatrix} 1&2\\1&-1 \end{pmatrix}I \begin{pmatrix} 1&2\\1&-1 \end{pmatrix}^T \right) = \mathcal{N}\left( 0, \begin{pmatrix} 5&-1\\-1&2 \end{pmatrix} \right) \end{equation}\]对于这种情况,我们在这里直接阐述两个事实。
第一,我们可以把 $X+2Y\mid X-Y$ 这个整体看作一个随机变量 $Z$,且这个随机变量 $Z$ 是也是服从高斯分布:$Z=(X+2Y\mid X-Y)\sim\mathcal{N}(\mu_{X+2Y\mid X-Y},\Sigma_{X+2Y\mid X-Y})$。
其中,条件期望和条件协方差的形式我们在上一篇文章中已经详细推导过了:
\[\begin{equation} \begin{aligned} \mu_{X+2Y\mid X-Y} &= \mu_{X+2Y}+\Sigma_{X+2Y, X-Y}\Sigma_{X-Y}^{-1}\left(X-Y-\mu_{X-Y}\right)\\ &=0-1\cdot\frac{1}{2}\cdot\left(X-Y-0\right)\\ &=-\frac{1}{2}(X-Y)\\ \Sigma_{X+2Y\mid X-Y} &= \Sigma_{X+2Y}-\Sigma_{X+2Y, X-Y}\Sigma_{X-Y}^{-1}\Sigma_{X+2Y,X-Y}\\ &= 5-\frac{1}{2}\\ &= \frac{9}{2} \end{aligned} \end{equation}\]因此,$Z\sim\mathcal{N}(-\frac{1}{2}(X-Y),\frac{9}{2})$。
第二,对于任意可测函数 $g$,我们有 $\mathbb{E}[g(X+2Y)\mid X-Y]=\mathbb{E}[g(Z)]$。
因此,
\[\begin{equation} \begin{aligned} \mathbb{E}[(X+2Y)^2\mid X-Y] &=\mathbb{E}[Z^2]\\ &= \text{Var}[Z]+\text{E}[Z]^2\\ &= \frac{9}{2}+\left(-\frac{1}{2}(X-Y)\right)^2\\ &= \frac{9}{2}+\frac{1}{4}(X-Y)^2 \end{aligned} \end{equation}\]