- FlashAttention 系列
- NVIDIA Nemotron 3 Super 技术解读
| FA-v1 | FA-v2 | FA-v3 | FA-v4 | |
|---|---|---|---|---|
| 目标硬件 | Ampere | Ampere/Hopper | Hopper | Blackwell |
| 核心创新 | Tiled Attention + Online Softmax | 序列并行 + Split-Q | Warp 专业化 + 异步 | 5 级流水线 + 软件模拟指数 |
| 并行策略 | Batch/Head | Sequence | Warp-Group | Warp-Specialized |
| 精度支持 | FP16/BF16 | FP16/BF16 | FP8/FP16/BF16 | FP8/FP16/BF16 |
| 流水线级数 | 1 | 1 | 2 | 5 |
| 编程模型 | CUDA | CUDA | CUDA + WGMMA | CuTeDSL |
| 性能提升 | 2~4× over vanilla attention | 2× over FA-v1 | 2× over FA-v2 | 1.5~3× over FA-v3 |
TL;DR
FlashAttention (FA) 是由 Tri Dao 等人提出的一种 IO-Aware 的精确注意力机制。它指出在现代 GPU 架构上,注意力机制的真正瓶颈在于内存,而非计算。通过优化 GPU 内存层次结构中的数据移动,FlashAttention 可以实现比标准注意力几倍甚至十几倍的加速。由于它是一种精确注意力,因此它与原始注意力机制在数学上是等价的。
目前,FlashAttention系列一共有4代方法,每一代都针对不同的问题进行改进:
- v1:怎样避免把完整 attention 矩阵写回 HBM?
- v2:怎样在 GPU 上把并行性用得更充分?
- v3:怎样吃到 Hopper 的异步执行能力和低精度能力?
- v4:在 Blackwell 上,tensor core 的增长速度比其他部件更快,流水线该怎么重新设计?
零、FlashAttention概览
0.1. 现代GPU内存架构
现代GPU的内存是一个多级架构,一般可以分为如下四级:
| 层级 | 容量 | 带宽 | 延迟 | 控制方式 |
|---|---|---|---|---|
| Register | 256 KB/SM | ~ 100 TB/s | 0 周期 | 透明 |
| SRAM | 192 KB/SM | ~ 19 TB/s | ~ 20 周期 | 显式管理 |
| L2 Cache | 40~50 MB | ~ 12 TB/s | ~ 200 周期 | 透明 |
| HBM | 40~80 MB | ~ 1.5 TB/s | ~ 500 周期 | 显式管理 |
从上表可以看到:
- SRAM 比 HBM 快 10 倍(带宽)
- SRAM 比 HBM 小 1000 倍(容量)
因此,GPU 中数据移动的成本远大于计算成本。
0.2. Attention 是内存瓶颈而非计算瓶颈
在现代GPU内存架构下,标准的Attention实现包括下面的几步:
- 读入 $Q$ 和 $K$(两次 HBM -> SRAM)
- 在 SRAM 中计算注意力分数矩阵 $S = QK^T$
- 写回 $S$(SRAM -> HBM)
- 读入 $S$(HBM -> SRAM)
- 经过缩放、mask、Softmax 得到注意力权重矩阵 $P$
- 写回 $P$(SRAM -> HBM)
- 读入 $P$ 和 $V$(两次 HBM -> SRAM)
- 在 SRAM 中计算 $O = PV$
- 写回 $O$(SRAM -> HBM)
整个过程共需要5次从 SRAM 到 HBM、3次从HBM 到 SRAM 的数据移动,且注意力矩阵 $S$ 和 $P$ 的大小都是 $O(N^2)$ 的,当序列变长时,需要大量带宽在HBM和SRAM之间传输数据。
0.3. FlashAttention 的核心思想
FlashAttention 策略可以用以下三点来概括:
- 将数据分块(Tiling),使每块能完全放入 SRAM
- 在 SRAM 内完成完整的注意力计算
- 最小化 HBM 和 SRAM 之间数据移动
为此,FlashAttention 的主要步骤如下:
- 载入一块 query、key 和 value
- 计算这一块的局部贡献
- 更新运行中的 Softmax 统计量并累积输出
- 继续处理下一个 tile
这样一来,kernel 就可以把中间结果尽可能留在靠近计算单元的地方,而不是频繁地丢回慢速的 HBM。
一、FlashAttention-v1:IO 感知注意力
📖 (NeurIPS’22) FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
🔗 https://arxiv.org/abs/2205.14135
1.1. TL;DR
Motivation
- 注意力机制的平方复杂度限制了 Transformer 高效处理长输入序列。使用标准注意力机制处理长度上千的序列时就很容易 OOM。
- 近似注意力方法通过减少 FLOPs 来加速计算,但由于内存访问模式效率低下和大量的 I/O 开销,加速比往往比较低,而且还损失了 Attention 的精度。
Methodology
- FA-v1 是一种 I/O 感知的精确注意力机制,最大程度上减少了 SRAM 和 HBM 之间的数据移动,以减少内存瓶颈。
- FA-v1 利用分块和平铺以及在 SRAM 内增量计算 Softmax,分块处理注意力,而无需在 HBM 中 materialize 完整的 $O(N^2)$ 注意力矩阵。
- 前向过程的激活值不存储在 HBM 上,而是在反向传播时重新计算激活值,进一步减少了内存使用,并且所有操作都融合到一个 CUDA kernel 中,以最大限度地减少读写 HBM 的次数。
Results
- BERT-large 训练加速15%,GPT-2 训练加速高达3倍,同时保持相同的模型质量。
- 将注意力的内存占用从 $O(N^2)$ 降低到 $O(N)$,使得 Transformer 能够处理长达 64K 的序列,显著超过了以往的可行长度。
1.2. FA-v1 的核心创新
创新 1:Tilded Attention(分块注意力)
将 $Q,K,V$ 分块 (Tile),每次从 HBM 上加载一块到 SRAM,在 SRAM 内计算完整注意力,只把最终的输出 $O$ 写回 HBM 上。
块大小一般设置为 $B = \lfloor\frac{M}{4d}\rfloor$,其中 $M$ 是 SRAM 大小,$d$ 是隐藏维度。对于一张 A100 GPU,$M$ = 192KB,$d$ = 64,此时 $B$ = 750。也就是一次性加载 750 个 token 进入 SRAM。
创新 2:Online Softmax(在线 Softmax)
虽然 $Q,K,V$ 可以分块计算,但对分数矩阵 $S$ 的 Softmax 操作需要全局的序列(需要最大值以及计算归一化因子),无法分块计算。
标准的 Softmax 需要3次遍历序列:
- Pass 1:计算全局最大值 $m = \max_i x_i$
- Pass 2:计算归一化因子 $d = \sum_i \exp(x_i - m)$
- Pass 3:计算每个位置的输出值 $\text{softmax}(x)_i = \frac{\exp(x_i - m)}{d}$
而 Online Softmax 则通过维护两个运行时统计量 $(m, \ell)$,能够在 2 次遍历之内增量计算全局 Softmax。其中:
- $m$: 当前最大值
- $\ell$: 当前归一化因子 $\sum \exp(x_i - m)$
Online Softmax 的更新公式如下:
\[\begin{equation} \begin{aligned} m_{\text{new}} &= \max\left(m_{\text{old}}, m_{\text{block}}\right)\\ \ell_{\text{new}} &= \exp\left(m_{\text{old}} - m_{\text{new}}\right) \cdot \ell_{\text{old}} + \exp\left(m_{\text{block}} - m_{\text{new}}\right) \cdot \ell_{\text{block}}\\ O_{\text{new}} &= \text{diag}\left(\ell_{\text{new}}\right)^{-1} \left( \text{diag}(\ell_{\text{old}}) \exp\left(m_{\text{old}} - m_{\text{new}}\right) O_{\text{old}} + \exp\left(m_{\text{block}} - m_{\text{new}}\right) \tilde{V} \right) \end{aligned} \end{equation}\]# FlashAttention-v1 前向传播伪代码
def flash_attention_forward(Q, K, V):
# 初始化
O = zeros(N, d) # 输出
l = zeros(N) # 归一化因子
m = -inf * ones(N) # 最大值
# 分块
Bc = M // (4*d) # K,V 块大小
Br = min(Bc, d) # Q 块大小
# 外循环:遍历 K,V 块
for j in range(Tc): # Tc = N/Bc
# 加载 K_j, V_j 到 SRAM
K_j = load_from_HBM(K, j*Bc, Bc)
V_j = load_from_HBM(V, j*Bc, Bc)
# 内循环:遍历 Q 块
for i in range(Tr): # Tr = N/Br
# 加载 Q_i, O_i, l_i, m_i 到 SRAM
Q_i = load_from_HBM(Q, i*Br, Br)
O_i = load_from_HBM(O, i*Br, Br)
l_i = load_from_HBM(l, i*Br, Br)
m_i = load_from_HBM(m, i*Br, Br)
# SRAM 内计算
S_ij = Q_i @ K_j.T # 注意力分数
m_ij = rowmax(S_ij) # 块内最大值
P_ij = exp(S_ij - m_ij) # 归一化前
l_ij = rowsum(P_ij) # 块内归一化因子
# 更新统计量
m_new = max(m_i, m_ij)
l_new = exp(m_i - m_new) * l_i + exp(m_ij - m_new) * l_ij
# 更新输出
V_ij = P_ij @ V_j
O_new = (exp(m_i - m_new) * l_i * O_i + exp(m_ij - m_new) * V_ij) / l_new
# 写回 HBM
write_to_HBM(O, i*Br, O_new)
write_to_HBM(l, i*Br, l_new)
write_to_HBM(m, i*Br, m_new)
return O
创新 3:Recomputation(激活值重计算)
在标准反向传播中,需要存储 $O(N^2)$ 的注意力矩阵 $P$。FlashAttention 在反向传播期间,重新在芯片上根据需要计算注意力块。虽然这增加了总的 FLOPs,但它显著降低了内存带宽需求,而内存带宽是现代 GPU 的主要瓶颈。
前向过程中保存的状态(只需 $O(N)$ 内存):
- $Q, K, V, O$ 矩阵(大小均为 $O(N×d)$)
- 两个统计量 $m$ 和 $\ell$
- Dropout 随机种子
反向传播过程:
- 重新加载 $Q,K,V$ 块到 SRAM
- 使用保存的统计量重新计算 $P$
- 计算梯度并累加
创新 4:Kernel Fusion(内核融合)
FlashAttention 将所有注意力操作,包括矩阵乘法、掩码、Softmax、Dropout 和最终输出计算,都在一个单独的 CUDA Kernel 中实现。内核融合消除了单独操作时可能发生的中间内存写入和读取,最大限度地提高了快速片上内存中的数据重用。
1.3. 复杂度分析
| 标准注意力 | FlashAttention | |
|---|---|---|
| 时间复杂度 | $O(N^2d)$ | $O(N^2d)$ |
| 空间复杂度 | $O(N^2)$ | $O(N)$ |
| IO 复杂度 | $O(N^2)$ | $O(N^2d^2/M)$ |
FlashAttention 的 IO 复杂度 $O(N²d²/M)$ 是渐进最优的。基于 Red-Blue Pebble Game 模型的理论证明,任何精确注意力算法必须 $\Omega(N²d²/M)$ 次 HBM 访问
1.4. 实验结果
FlashAttention-v1 在 A100 上能够达到30-50%的硬件利用率。
| 吞吐量 (TFLOPs/s) | 2K 长度 | 8K 长度 | 16K 长度 |
|---|---|---|---|
| 标准注意力 | ~40 | OOM | OOM |
| FlashAttention-v1 | ~110 | ~120 | ~125 |
| 加速比 | 2.75 | - | - |
二、FlashAttention-v2:更好的并行性,更好的工作分区
📖 (ICML’23) FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
🔗 https://arxiv.org/abs/2307.08691
2.1. TL;DR
Motivation
- 原始的 FlashAttention 算法虽然内存高效,但由于工作分区效率低下和线程块间并行化不佳,在GPU 利用率方面仍存在局限性。
Methodology
- 除了在 batch 和 head 维度并行之外,引入了序列维度的并行化,以提高GPU占用率。
- 优化了 GPU 线程块内部和 warp 之间的工作分区,以减少不必要的共享内存访问并提高数据局部性。
- 最小化非矩阵乘法操作,以更好地利用 GPU 上专门的 Tensor Cores,这些核心在矩阵计算方面效率极高。
Results
- 在 A100 上比 v1 提速约2倍,比标准注意力快3-4倍。
- A100 上吞吐量达到理论最大值的73%,H100 上达到335 TFLOPs/s。
- 与 v1 相比,它在端到端模型训练中实现1.3倍加速,由于内存效率更高,可支持更大的上下文长度和批处理大小。
2.2. FA-v1 的瓶颈分析
瓶颈 1:并行度不足(低占用率)
FA1 并行策略是按 batch 和 head 并行,Thread Blocks 的数量为 batch_size × n_heads
在长上下文场景中,为了避免OOM,会将 batch_size 和 n_heads 都设置得比较小。此时 Thread Blocks 的数量很少,GPU 中有大量的 SM 闲置。
瓶颈 2:非矩阵乘法开销
- GEMM 操作放在专用的 Tensor Core 上进行,吞吐量非常大(A100 上能达到312 TFLOPs/s)
- 非 GEMM 操作(exp、除法)需要在 SFU (Special Function Unit) 上进行,吞吐量较少(A100 上仅有19.5 TFLOPs/s)
二者的吞吐量差了整整16倍。FA-v1 中,每次迭代都做需要做 exp 和除法操作,SFU 成为瓶颈。
2.3. FA-v2 的核心优化
优化 1:延迟归一化来减少非 GEMM 操作的 FLOPs
FA-v1 在每一步迭代都除归一化因子,FA-v2 改为仅在输出前最后一步才除,只需要一次除法操作。
优化 2:循环顺序 Split-K → Split-Q
FA-v2 优化了注意力的循环顺序,先循环 Q 再循环 KV:
# FA-v1 循环顺序(Split-K):
for j in range(Tc): # 外循环:K,V 块
for i in range(Tr): # 内循环:Q 块
# 需要原子操作累加 O_i
# FA-v2 循环顺序(Split-Q):
for i in range(Tr): # 外循环:Q 块
for j in range(Tc): # 内循环:K,V 块
# O_i 完全在寄存器内累加,无需原子操作
# 只写一次 O_i 到 HBM
这样做有三个好处:
- 输出块 O_i 一直保存在寄存器中
- 无需原子操作或线程块间同步
- HBM 写入次数从 $O(Tc×Tr)$ 降至 $O(Tr)$
优化 3:增加序列并行
FA-v2 增加按序列长度的并行,将序列的不同部分分配给不同的块,充分占满所有的 SM。
优化 4:warp 分区改进
FA-v2 不是让所有 warp 访问相同的数据,而是将数据的特定部分分配给不同的 warp,以此减少了共享内存访问竞争。
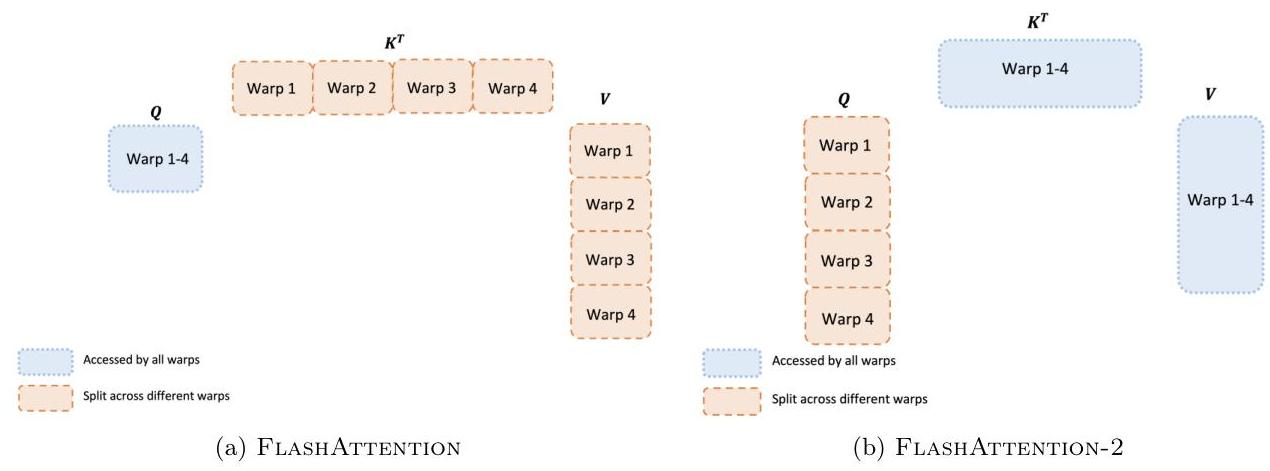
FA-v1 使用 Split-K 的方式,每个 warp 计算各自的 $K$ 切片,并通过共享内存同步给其他 warp。
FA-v2 改为 Split-Q 的方式,每个 warp 处理不相交的 $Q$ 切片,无需 warp 间通信,输出直接写入一个独立区域。
2.4. 实验结果
| 吞吐量 (TFLOPs/s) | 2K 长度 | 8K 长度 | 16K 长度 |
|---|---|---|---|
| FlashAttention-v1 | ~110 | ~120 | ~125 |
| FlashAttention-v2 | ~200 | ~220 | ~225 |
| 加速比 | 1.8 | 1.8 | 1.8 |
A100 利用率约 73%,接近 GEMM 的 80-90%。
三、FlashAttention-v3:Hopper 架构上的异步与低精度
📖 (NeurIPS’24) FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
🔗 https://arxiv.org/abs/2407.08608
3.1. TL;DR
Motivation
- FA-v2 未能充分利用现代 GPU 硬件特性,在Hopper 架构上仅达到 35% 的利用率。
- 在使用低精度 (FP8) 进行计算时,LLM 经常出现异常值。
Methodology
- 使用 warp 专业化实现生产者-消费者异步,专门分配 warp 用于通过 Hopper 的 TMA 进行异步数据移动以及 Tensor Core 计算。
- 在 warp group 内采用两阶段流水线,通过将非 GEMM 操作与异步 GEMM 重叠来隐藏其延迟。
- 通过 WGMMA 集成 FP8 Tensor Core,设置专用指令实现高效数据布局,并引入带非相干处理 (Incoherent Processing) 的分块量化 (Block Quantization) 以提高数值精度。
Results
- 与 FA-v2 相比,在 FP16/BF16 的前向传播中实现了高达 2.0 倍的速度提升,在反向传播中实现了 1.5-1.75 倍的速度提升,达到 H100 理论峰值吞吐量的 75%。
- 在 FP8 精度下达到接近 1.2 PFLOPs/s 的吞吐量。
- 与基线相比,FP8 数值精度提高了 2.6 倍,在存在异常特征的情况下精度提升更明显。
3.2. Hopper 架构新特性
- WGMMA (Warp-Group Matrix Multiply-Accumulate):异步执行的 GEMM 指令,能达到 50% 更高吞吐量
- TMA (Tensor Memory Accelerator) :异步数据加载的专用硬件单元
- 异步执行模型:计算和数据传输可并行
- FP8 Tensor Core:E4M3/E5M2 格式,2倍吞吐量
3.3. FA-v2 在 Hopper 上的瓶颈
尽管 FA-v2 在 A100 上表现良好,但在 H100 上仅达到 35% 利用率。
瓶颈 1:同步执行模型
FA-v2 使用 Ampere 架构下的 mma.sync 指令,未利用 Hopper 的异步 WGMMA 指令。
瓶颈 2:无生产者 - 消费者重叠
FA-v2 中数据加载和计算串行执行
瓶颈 3:非 GEMM 操作瓶颈
H100 中 Tensor Core 达到 989 TFLOPs,而 SFU 仅有 3.9 TFLOPs,二者的差距进一步拉大(256× 差距)
3.4. FA-v3 的核心创新
创新 1:warp 专业化(生产者 - 消费者模型)
在 FA-v3 中,一个 thread block 中的 10 个 warp 有不同的分工:
- Producer Warp Group (2 个 warp):专门负责执行 TMA 指令,从 HBM 异步加载数据到共享内存环形缓冲区
- Consumer Warp Group (8 个 warp):专门执行 WGMMA 和 Softmax,从共享内存读取数据
创新 2:GEMM-Softmax 流水线(Pingpong 调度)

FA-v2 中按照 GEMM -> Softmax -> GEMM 的顺序串行执行,存在顺序依赖。
为了解决较快的 GEMM 和较慢的 Softmax 之间的性能差异,FA-v3 采用了乒乓调度方案,在一个 warp group 执行 Softmax 计算时,另一个 warp group 同时执行异步 GEMM。
创新 3:低精度与块量化
FA-v3 的 FP8 实现通过 WGMMA 指令直接利用 Hopper 的 FP8 Tensor Core,目标是使吞吐量比 FP16 翻倍。然而,这需要解决几个技术挑战。
- 布局转换。FP8 WGMMA 要求 K-major 格式(在 head 维度上连续),而第二个 GEMM 操作 ($O=PV$) 中 V 通常是 row-major 格式(在 seq_len 维度上连续)。FA-v3 让 Producer Warp Group 使用
ldmatrix(加载矩阵)和stmatrix(存储矩阵)指令执行高效的核内转置,这些指令可以在内存操作期间进行转置,而无需额外开销。 - 其次是量化误差。FP8 E4M3 只有 3 位尾数,对异常值比较敏感。为此,FA-v3 采用了两种关键技术:
- 分块量化 (Block Quantization):对每个块使用单独的缩放因子。这考虑了不同张量区域的幅度变化,并且可以与 RoPE 等前置操作融合。
- 非相干处理 (Incoherent Processing):为了处理异常值,Q 和 K 矩阵在量化前乘以一个随机正交矩阵 M。正交矩阵具有内积不变性,因此可以在保持注意力分数的同时,通过分散异常值使分布更适合量化。
3.5. 实验结果
| 带宽 TFLOPs | FA-v2 | FA-v3 | 加速比 |
|---|---|---|---|
| FP16 | 350 | 740 | 2.1 |
| FP8 | N/A | 1200+ | - |
| GPU 利用率 | 35% | 75~85% | 2.2 |
四、FlashAttention-v4:Blackwell 优化
📖 FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling 🔗 https://arxiv.org/abs/2603.05451
4.1. TL;DR
Motivation
- Blackwell 架构引入了不对称的硬件扩展,Tensor Core 的吞吐量翻倍,而 HBM 带宽和指数单元吞吐量增长慢得多,从而转移了性能瓶颈。
Methodology
- 针对 Blackwell 的异步 MMA 操作和更大的 Tile 进行了优化,以最大化计算和内存操作的重叠。
- 指数单元瓶颈通过使用 FMA 单元软件模拟指数函数和条件 Softmax 重缩放来缓解,以减少不必要的非 GEMM 操作。
- 通过利用 Blackwell 的张量内存 (TMEM) 存储中间结果,并利用 2-CTA(协同线程阵列)MMA 模式进行反向传播,减少了共享内存流量。
- 整个实现使用 CuTe-DSL 完成,提供完整的底层控制,并显著加快了 JIT 编译时间。
Results
- FA-v4 在 B200 GPU 上实现了高达 1613 TFLOPs/s 的吞吐量,达到了理论最大值的约 71%。
- 前向传播比 cuDNN 提速 1.3 倍,比 Triton 实现提速 2.7 倍。
- 确定性反向传播保持了非确定性对应版本高达 75% 的速度,实现了可重现的训练,且性能开销最小。
- 与基于 C++ 模板的方法相比,编译时间减少了 20-30 倍,显示了开发者生产力的显著提升。
4.2. Blackwell 架构的新特性
- 张量内存 (TMEM):每个 SM 上 256 KB 的片上内存,用于保存 Tensor Core 的中间结果
- 更大的 MMA Tile:128×128,面积是 Hopper 64×128 的两倍
- 完全异步的 Tensor Core 核心操作:MMA 直接异步写入 TMEM
- 2-CTA MMA 模式:协作线程数组可以执行具有分布式内存的单个 MMA
在 Blackwell 架构中,Tensor Core 更快,但 SFU 未同步升级。Softmax 中的指数运算现在与 GEMM 的耗时相当。
4.3. FA-v4 的核心创新
创新 1:5 级异步流水线
5 个 Warp Group 并行执行不同阶段:
- Load Warp:从 HBM 异步加载数据到 SMEM
- MMA Warp:执行 TCGEN05 矩阵乘法
- Softmax Warp:使用专用的 CUDA Core 计算指数和归一化因子
- Correction Warp:应用校正因子和量化
- Store Warp:异步写回结果到 HBM
创新 2:软件模拟指数计算
Blackwell 上 SFU 数量远少于 CUDA Core,成为瓶颈。
FA-v4 使用 FMA 单元上的多项式逼近来实现指数函数的软件模拟:把 2^x 分解为整数部分和小数部分的指数运算。小数部分使用 3 次多项式逼近,允许指数计算在 FMA 单元上并行运行,具有显着更高的吞吐量。
创新 3:CuTe-DSL
CuTe-DSL (CUDA Tensor Expression-Domain Specific Language) 是 NVIDIA CUTLASS 团队推出的 Python DSL,具有以下优势:
- 完全表达能力:与基于 C++ 的CUTLASS 有着相同的低级控制
- 快速编译:与C++模板方法相比,编译时间快20-30倍
- 可扩展性:降低GPU内核开发的门槛