- FlashAttention 系列
- NVIDIA Nemotron 3 Super 技术解读

一、模型核心规格
Nemotron 3 Super 具有 120B-A12B 的参数量,原生支持 1M token 的上下文,并使用 NVFP4 四精度预训练。
这种设计使得模型在保持大容量的同时,推理成本相对可控。120B 的总参数量提供了足够的知识存储和表达能力,而每 token 仅激活 12B 参数则保证了推理效率。100 万 token 的上下文窗口对于需要处理长代码库、长文档或多轮对话的智能体应用尤为重要。
二、架构创新
2.1 混合 Mamba-Transformer-MoE

Nemotron 3 Super 的骨干网络由三种类型的层交错组成:
- Mamba-2 层:SSM 模型提供 $O(n)$ 级的线性时间复杂度,这是实现 1M token 上下文窗口的关键。当 Agent 需要推理整个代码库、长对话历史或检索文档堆栈时,Mamba 层能够保持可管理的内存占用。
- Transformer Attention 层:纯 SSM 在精确关联回忆任务上可能存在困难,例如需要在长上下文中定位特定信息。Transformer 的注意力层保留了这种能力,确保模型在复杂信息检索任务中保持高保真度。
- Latent MoE 层:MoE 层在不增加密集计算成本的前提下扩展有效参数数量。每个 token 仅激活专家子集,保持低延迟和高吞吐量(下一节中详细介绍)。
这种混合架构的设计哲学是:Mamba 负责序列处理效率,Transformer 负责精确推理,MoE 负责参数效率。三者结合实现了效率与能力的平衡。
2.2 Latent MoE:硬件感知的专家设计
Latent MoE 是 Nemotron 3 Super 的核心架构创新之一。
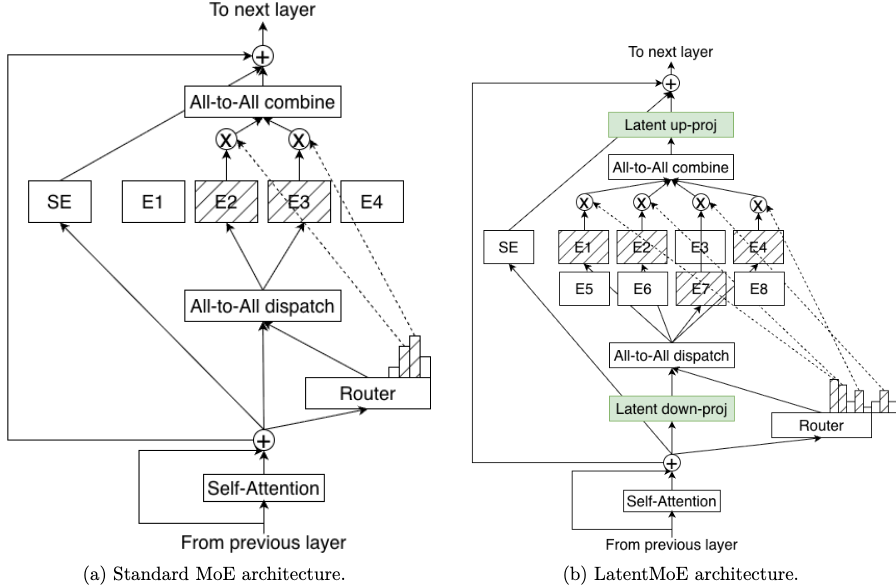
- 在标准的 MoE 架构中,token 直接从模型的完整隐藏维度路由到各个专家。随着模型规模增长,这个路由层会成为瓶颈,增加计算成本并限制可部署的专家数量。
- Latent MoE 在路由决策之前,先将 token embedding 投影到压缩的 Low-Rank Latent Space,专家计算在这个较小维度中进行,结果再投影回完整模型维度。
这种设计带来两个实际优势:
- 相同成本下可以设置更多专家:通过在专家计算前压缩 token,模型能够以相同的计算成本咨询四倍数量的专家。这意味着模型可以获得更细粒度的专业化能力。
- 更细粒度的专业化:可用专家数量增加后,模型可以实现高度专业化的路由。例如,Python 语法和 SQL 逻辑可以激活不同的专家,这些专家仅在严格必要时才被调用。这种粒度在智能体场景中特别有价值,因为单次对话可能在几轮之内跨越工具调用、代码生成、数据分析和对话推理等多种任务。
2.3 Multi-Token Prediction
Nemotron 3 Super 采用多 Token 预测训练,专门的预测头从每个位置同时预测多个未来 token。这一设计带来两个具体好处:
- 训练时更强的推理能力:预测多个未来 token 迫使模型内化更长程的结构和逻辑依赖。模型不是学习猜测合理的下一个词,而是必须学习预测连贯的序列。这在思维链任务上产生可测量的提升,因为每一步都必须从最后一步逻辑地推导出来。
- 推理时内置推测解码:通过在一次前向传播中同时预测多个未来 token,MTP 显著减少了生成长序列所需的时间。MTP 头提供可以并行验证的草稿预测,对于代码和工具调用等结构化生成任务,无需单独的草稿模型即可实现最高三倍的时钟速度提升。
与为每个偏移量训练独立预测头的架构不同,Nemotron 3 Super 在所有 MTP 头上使用共享权重设计。这使得参数开销最小化,同时提高训练稳定性,各个头学习就连贯的续写达成一致,而不是分散到特定于偏移量的捷径。相同的权重共享也使得推测草稿在更长草稿长度下更加一致,而这正是独立训练的头通常退化的地方。
2.4 原生 NVFP4 预训练
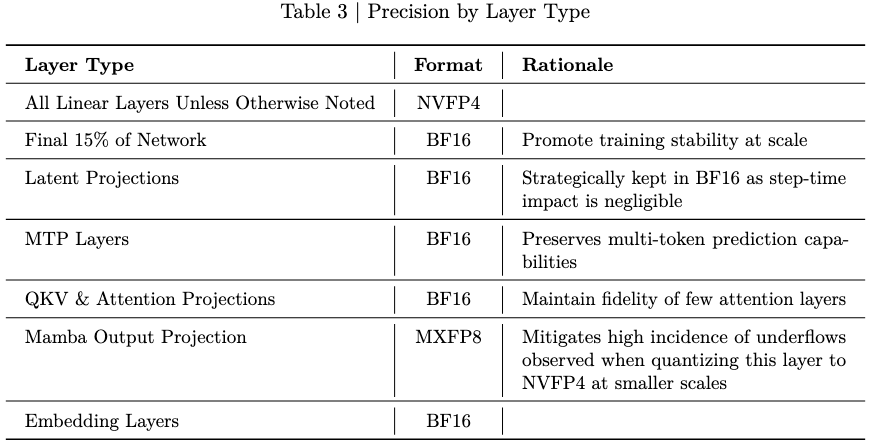
大多数量化模型从全精度开始训练,然后在训练后压缩,这不可避免地引入精度损失。Nemotron 3 Super 采用不同的方法:预训练期间大部分浮点乘加运算在 NVFP4 格式下运行,这是 NVIDIA 优化的四精度浮点格式。
此外,Nemotron 3 Super 还针对 Blackwell 架构优化,这显著降低了内存需求,与 H100 上的 FP8 相比,在 B200 上推理速度提升四倍,同时保持精度。
原生降低精度训练意味着模型从第一次梯度更新开始就学习在四比特算术的约束下保持准确。结果是一个在显著降低的内存占用下运行,同时在数学上稳定且准确的模型。
三、训练方法
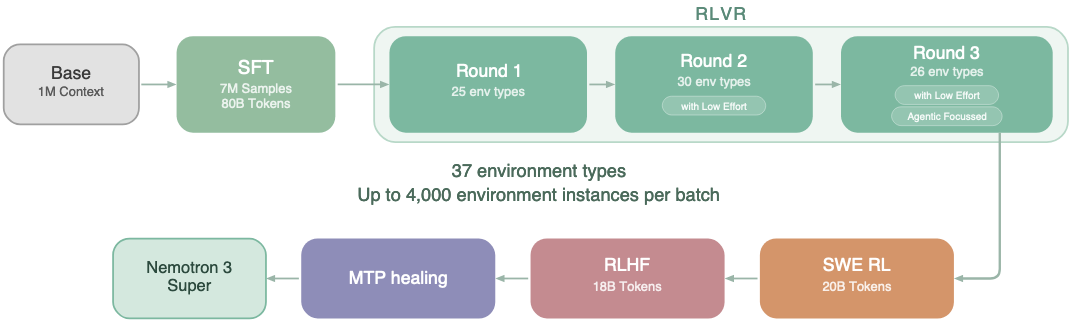
3.1 Pretraining
Nemotron 3 Super 使用 NVFP4 在 25T token 数据集上进行预训练。模型不是事后量化全精度模型,而是从第一次梯度更新开始就以降低的精度原生训练。这意味着模型在整个预训练过程中学习在 4 bit 算术的约束下保持准确,而不仅仅是在推理时。
3.2 SFT
在强化学习之前,Nemotron 3 Super 在约 7M 个监督微调样本上进行微调。这些样本来自 4000 万个样本的更广泛后训练语料库,涵盖推理、Instruction Following、Coding、安全和 Multi-Agent 任务。
这一阶段建立了行为基础,强化学习随后在此基础上进行优化。模型学习跨任务类型的正确响应格式和结构,为后续强化学习阶段提供稳定的起点,而不是从原始预训练检查点开始优化。
3.3 多环境 RL
为了使 Nemotron 3 Super 与真实的 Agent 行为对齐,模型使用强化学习在 NeMo Gym 中的多样化环境中进行 GRPO 后训练。NeMo Gym 是 NVIDIA 用于构建和扩展强化学习训练环境的开源库。
这些环境评估模型执行动作序列的能力,生成正确的工具调用、编写功能性代码、产生满足可验证标准的多部分计划,而不仅仅是提供令人满意的单轮响应。这些轨迹构成了使用 NeMo RL 开源库大规模运行强化学习的核心训练数据。
这种基于轨迹的强化学习产生了一个在多步工作流下可靠行为、减少推理漂移并处理智能体管道中常见结构化操作的模型。强化学习阶段使用了超过 1.2M 个环境 rollout,跨越 21 种环境配置。
四、性能表现
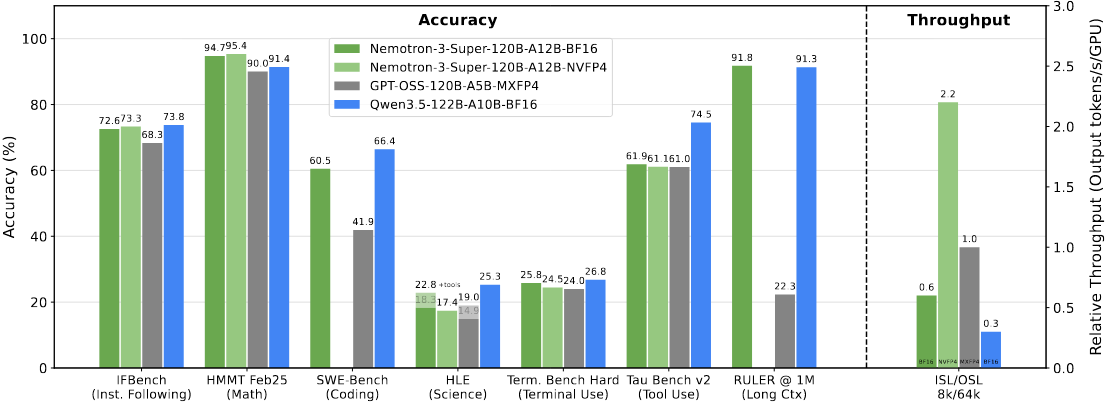
Nemotron 3 Super 在多个重要的智能体基准测试中实现了领先的准确性,同时保持了令人难以置信的吞吐量。
- 在 PinchBench 基准测试中,Nemotron 3 Super 得分为 85.6%,使其成为同类中最好的开源模型。PinchBench 是一个用于确定大语言模型作为智能体大脑表现如何的新基准。
- 与前一版本相比,Nemotron 3 Super 的吞吐量提升超过五倍,内存和计算效率提升四倍。这些改进对于需要连续大规模运行的多智能体应用尤为重要。
五、部署建议
NVIDIA 提出了 Super + Nano 的部署模式。Nemotron 3 Nano 更适合在 Agent Workflow 中执行有针对性的单个步骤时实现高准确性的优秀选择。当多智能体应用升级到复杂的多步骤活动时,它们需要高容量模型来进行卓越的规划和推理,此时就需要 Nemotron 3 Super 来处理复杂任务。这种组合部署的思路是:用小模型处理简单任务,大模型处理复杂规划,在成本和效果之间取得平衡。
在软件开发场景中,简单的合并请求可以由 Nemotron 3 Nano 处理,而需要更深入理解代码库的复杂编码任务可以由 Nemotron 3 Super 处理。专家级编码任务则可以由专有模型处理。