一、对泊松分布的深入认识
上一篇文章的最后我们提出了这样一个问题。考虑下面的条件期望:
\[\begin{equation} \mathbb{E}[S_4\mid N(1)=2] \end{equation}\]如下图所示,我们现在有三种观点:
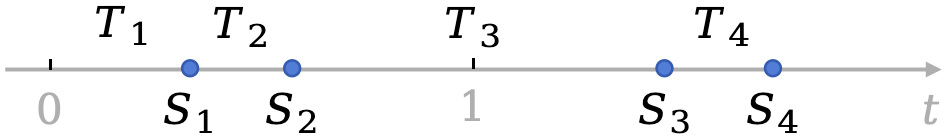
- $[S_2,S_3]$ 的长度服从参数为 $\lambda$ 的指数分布。
- 当我们在 $[S_2,S_3]$ 内增加一个确定的时间点 $t=1$,由于指数分布具有无记忆性,$[1,S_3]$ 的长度也服从指数分布,但具体的参数未知。
- 上面条件期望的期望值为 $1+2/\lambda$。由于 $[S_3,S_4]$ 的长度期望为 $1/\lambda$,因此这意味着 $[1,S_3]$ 的长度期望也是 $1/\lambda$。
这三个条件是互斥的,不可能全部正确。
我们现在来考察 $[S_{n-1},S_n]$ 的长度 $T_n$。注意到,第 $n$ 次事件发生的间隔可以表示为:
\[\begin{equation} T_n=S_n-S_{n-1} \end{equation}\]当我们在 $[S_{n-1},S_n]$ 内增加一个确定的时间点 $t$ 时,前后事件的下标就变成了一个随机变量,而不是一个确定值 $n$:
- 由于前一次事件发生在 $t$ 之前,因此其下标应当是 $N(t)$。
- 同理,后一次事件的下标应当是 $N(t)+1$。
我们说 $T_n$ 服从参数为 $\lambda$ 的指数分布,这是有前提的,即下标 $n$ 是一个确定值。在我们这里,确定的只是观察的时间 $t$,但在这个时间之前发生了多少次事件 $N(t)$ 是一个随机变量。
也就是说,我们实际上在求下面的随机变量:
\[\begin{equation} T(t)=S_{N(t)+1}-S_{N(t)} \end{equation}\]这与上面的等式是不能划等号的,因为其下标有本质不同。
1.1. 给定发生次数下发生时刻的分布
下面我们来研究一下 $T(t)$ 的分布:
\[\begin{equation} \begin{aligned} F_{T(t)}(x) &= P(T(t)\leq x)\\ &= P(S_{N(t)+1}-S_{N(t)}\leq x)\\ &= \sum_{n=0}^{\infty} P(S_{n+1}-S_{n}\leq x\mid N(t)=n) P(N(t)=n) \end{aligned} \end{equation}\]解决问题的关键在于这个条件概率
\[\begin{equation} P(S_{n+1}-S_{n}\leq x\mid N(t)=n) \end{equation}\]真的就是指数分布吗?即条件 $N(t)=n$ 真的对前面的随机变量没有影响吗?
前面我们用过条件期望来分析随机个随机变量之和的期望。在那里我们特别强调,随机变量的个数 $N$ 是独立于这些随机变量 $X_1,X_2,\dots,X_n$ 的。这是因为我们希望将 $N$ 作为条件之后,不要对 $X_1,X_2,\dots,X_n$ 产生影响。
回到我们这个问题。当我们固定事件发生的次数 $N(t)=n$ 时,事件发生时刻 $S_n$ 的分布是否会受到影响呢?
1.1.1. 一个简单的例子
我们先从一个简单的例子开始。考虑 $N(t)=1$ 时,$S_1$ 的条件分布:
\[\begin{equation} \begin{aligned} F_{S_1\mid N(t)=1}(x) &= P(S_1\leq x\mid N(t)=1)\\ &= \frac{P(S_1\leq x, N(t)=1)}{P(N(t)=1)}\\ &= \frac{P(N(x)=1, N(t)-N(x)=0)}{P(N(t)=1)}\\ &= \frac{P(N(x)=1)P(N(t-x)=0)}{P(N(t)=1)}\\ &= \frac{\lambda x\exp(-\lambda x) \exp(-\lambda (t-x))}{\lambda t\exp(-\lambda t)}\\ &= \frac{x}{t} \end{aligned} \end{equation}\]因此,条件密度为:
\[\begin{equation} f_{S_1\mid N(t)=1}(x)=\frac{\mathrm{d}}{\mathrm{d}x}F_{S_1\mid N(t)=1}(x)=\frac{1}{t} \end{equation}\]在没有条件时,$S_1$ 应该服从指数分布。在加入条件 $N(t)=1$ 后,居然变成了均匀分布。
1.1.2. 微元法求解一般情况
显然,在给定条件 $N(t)=n$ 时,$S_n$ 的分布产生了变化。我们下面来研究这种情况。
\[\begin{equation} \begin{aligned} F_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n) &= P(S_1\leq x_1,\dots,S_n\leq x_n\mid N(t)=n) \end{aligned} \end{equation}\]这里很难再去做概率转换,因为情况实在是太多。这里我们需要使用微元法来求解,这是一种分析点过程的通用方法。
上面的式子中,我们只对每个随机变量设置了上界 $x_k$。而微元法则希望对每个随机变量都同时设置上界和下界:
\[\begin{equation} P(x_1\leq S_1\leq x_1+\Delta x_1,\dots,x_n\leq S_n\leq x_n+\Delta x_n\mid N(t)=n) \end{equation}\]也就是说,微元法是用一个个微元,把每个事件包围起来。只要令每个微元 $ \Delta x_k \to 0 $,我们就能够认为在每个微元中只发生了一次事件(泊松分布的稀疏性假设),且微元之外没有事件发生。也就是说:
- 有 $n$ 个时间区间,每个时间区间长度为 $\Delta x_k$。在每个区间内只发生了一次事件。
- 剩下的 $t-\Delta x_1-\cdots-\Delta x_n$ 时间内没有事件发生。
- 所有的时间区间内发生的次数都是相互独立的(独立增量)
更重要的是,求出上面这个概率之后,我们很简单就能直接得到我们想求的联合概率密度:
\[\begin{equation} \begin{aligned} &\quad\ f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n)\\ &= \lim_{\Delta x_k\to 0} \frac{P(x_1\leq S_1\leq x_1+\Delta x_1,\dots,x_n\leq S_n\leq x_n+\Delta x_n\mid N(t)=n)}{\Delta x_1\cdots\Delta x_n} \end{aligned} \end{equation}\]于是我们下面直接来计算:
\[\begin{equation} \begin{aligned} &\quad\ f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n)\\ &= \lim_{\Delta x_k\to 0} \frac{1}{\Delta x_1\cdots\Delta x_n} P(x_1\leq S_1\leq x_1+\Delta x_1,\dots,x_n\leq S_n\leq x_n+\Delta x_n\mid N(t)=n)\\ &= \lim_{\Delta x_k\to 0} \frac{1}{\Delta x_1\cdots\Delta x_n} \frac{P(x_1\leq S_1\leq x_1+\Delta x_1,\dots,x_n\leq S_n\leq x_n+\Delta x_n, N(t)=n)}{P(N(t)=n)}\\ &= \lim_{\Delta x_k\to 0} \frac{1}{\Delta x_1\cdots\Delta x_n} \frac{ \prod_{k=1}^n P(N(\Delta x_k)=1) \cdot P\left(N\left(t-\sum_{k=1}^{n}\Delta x_k\right)=0\right) }{P(N(t)=n)}\\ &= \lim_{\Delta x_k\to 0} \frac{1}{\Delta x_1\cdots\Delta x_n} \frac{ \prod_{k=1}^n \lambda\Delta x_k\exp(-\lambda\Delta x_k) \cdot \exp\left(-\lambda \left(t-\sum_{k=1}^{n}\Delta x_k\right)\right) }{\frac{(\lambda t)^n}{n!}\exp(-\lambda t)}\\ &= \lim_{\Delta x_k\to 0} \frac{n!}{t^n}\\ &= \frac{n!}{t^n} \end{aligned} \end{equation}\]这个结果看起来和 $n=1$ 的情况对应的上,但实际上这是错的,只有 $n=1$ 时才对得上。
一个显然的证据是,这个概率密度积分甚至不是 1:
\[\begin{equation} \int_{0}^{t}\cdots \int_{0}^{t} \frac{n!}{t^n} \mathrm{d}x_1\cdots\mathrm{d}x_n =n! \end{equation}\]这里的问题出在:我们没有考虑微元的位置顺序。我们上面的计算想要成立,必须满足如下的顺序:
\[\begin{equation} x_1\leq x_2\leq\cdots\leq x_n \end{equation}\]因此,正确的概率密度应该是这样的:
\[\begin{equation} f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n)= \begin{cases} \frac{n!}{t^n},&0\leq x_1\leq x_2\leq\cdots\leq x_n\leq t\\ 0,&\text{otherwise} \end{cases} \label{eq:T-t-distribution} \end{equation}\]我们在附录1中证明了这个概率密度的积分是1。虽然这个事情本身没什么信息量,但是其中用到的对称函数积分这个技巧是很重要的。
1.1.3. 从顺序统计量的角度理解 $S_n$ 的联合分布
现在我们来解释一下上面这个概率密度的概率含义。首先,我们引入一个新的概念,叫做顺序统计量 (order statistics)。
考虑一组独立同分布的随机变量 $X_1,\dots,X_n$,我们定义下面 $n$ 个顺序统计量:
\[\begin{equation} X_{(1)}\leq X_{(2)}\leq\cdots X_{(n)} \end{equation}\]由于随机变量是一个从样本空间 $\Omega$ 映射到实数集 $R$ 的函数,因此两个随机变量不能和数值一样比较大小。这里的 $X_{(1)}$ 是与 $X_1,\dots,X_n$ 都不一样的新的随机变量,其定义为
\[\begin{equation} X_{(1)}=\min(X_1,\dots,X_n) \end{equation}\]其他的同理。
可以证明(附录2),这 $n$ 个顺序统计量的联合概率密度为:
\[\begin{equation} f_{X_{(1)},\dots,X_{(n)}}(x_1,\dots,x_n)= \begin{cases} n!\prod_{k=1}^n f_{X_1}(x_k),& x_1\leq x_2\leq\dots\leq x_n\\ 0,& \text{otherwise} \end{cases} \end{equation}\]与 $S_n$ 的联合密度(公式 \eqref{eq:T-t-distribution})对比,我们就可以发现,$S_n$ 的联合分布是 $n$ 个均匀分布 $U[0,t]$ 的顺序统计量。
1.2. 两次事件发生被某个时间截断
考虑泊松过程中相邻的两次事件发生时刻 $S_n$ 和 $S_{n+1}$,我们在 $[S_n,S_{n+1}]$ 内增加一个确定的时间点 $t$。我们希望研究 $[t,S_{n+1}]$ 的长度 $A(t)$ 和 $[S_n,t]$ 的长度 $B(t)$ 各自服从什么分布以及二者的关系。
首先我们写出联合分布的形式:
\[\begin{equation} \begin{aligned} F_{A(t),B(t)}(x,y) &= P(A(t)\leq x, B(t)\leq y) \end{aligned} \end{equation}\]这个不太好分析,我们转而研究下面的联合概率:
\[\begin{equation} \begin{aligned} P(A(t)\gt x, B(t)\gt y) &= P(N(t+x)-N(t)=0, N(t)-N(t-y)=0)\\ &= P(N(x)=0, N(y)=0)\\ &= P(N(x+y)=0)\\ &= \exp(-\lambda (x+y)) \end{aligned} \end{equation}\]因此:
\[\begin{equation} \begin{aligned} P(A(t)\gt x) &= P(A(t)\gt x, B(t)\gt 0)\\ &= \exp(-\lambda x) \end{aligned} \end{equation}\]进而,
\[\begin{equation} \begin{aligned} P(A(t)\gt x,B(t)\leq y) &= P(A(t)\gt x)-P(A(t)\gt x, B(t)\gt y)\\ &= \exp(-\lambda x)-\exp(-\lambda (x+y)) \end{aligned} \end{equation}\]同理,
\[\begin{equation} \begin{aligned} P(A(t)\leq x,B(t)\gt y) &= P(B(t)\gt y)-P(A(t)\gt x, B(t)\gt y)\\ &= \exp(-\lambda y)-\exp(-\lambda (x+y)) \end{aligned} \end{equation}\]综上所述,
\[\begin{equation} \begin{aligned} F_{A(t),B(t)}(x,y) &= P(A(t)\leq x, B(t)\leq y)\\ &= 1-P(A(t)\gt x, B(t)\gt y)-P(A(t)\gt x,B(t)\leq y)-P(A(t)\leq x,B(t)\gt y)\\ &= 1-\exp(-\lambda x)-\exp(-\lambda y)+\exp(-\lambda (x+y))\\ &= (1-\exp(-\lambda x))(1-\exp(-\lambda y)) \end{aligned} \end{equation}\]因此,我们得出结论:$A(t)$ 和 $B(t)$ 都服从参数为 $\lambda$ 的指数分布,且二者独立。
其实这里有一些小瑕疵。泊松分布的起点是从 $0$ 开始的,因此 $B(t)$ 最长不会超过 $t$。说明 $B(t)$ 并不是一个标准的指数分布,而是做了 min 截断操作。
但我们只需要让泊松分布的起点从 $-\infty$ 开始,就可以得到标准的指数分布了。
二、过滤泊松过程
上面我们已经认识到关于泊松过程的这样一个事实。
-
在一般情况下,事件发生时刻 $S_n$ 是一个服从 Gamma 分布的随机变量。
\[\begin{equation} S_n\sim\text{Gamma}\left(n,\frac{1}{\lambda}\right) \end{equation}\] -
在给定事件发生次数 $N(t)=n$ 的条件下,事件发生时刻 $S_n$ 的条件联合分布
\[\begin{equation} S_1,S_2,\dots,S_n\mid N(t)=n \end{equation}\]则服从 $n$ 个 $U[0,t]$ 的顺序统计量,其概率密度由公式 \eqref{eq:T-t-distribution} 给出。
在这一节中,我们将利用这个认识,对泊松过程进行一个本质性的推广:去掉【独立增量】的条件。
2.1. 对独立增量的深入分析
泊松过程的独立增量性质是指:对于任意两段不重叠的时间段 $[t_1,t_2]$ 和 $[t_3,t_4]$,其中 $t_1\lt t_2\le t_3\lt t_4$,泊松过程在这两段时间内的增量 $N(t_4)-N(t_3)$ 与 $N(t_2)-N(t_1)$ 是相互独立的。
我们指出,独立增量的本质就是:在 $[t_3,t_4]$ 时间段内,$[t_1,t_2]$ 内发生事件的影响可以通过减法操作(即 $N(t_4)-N(t_3)$)完全抵消。也就是说,泊松过程在任意时间内发生事件的影响【不随时间变化】。
Note:非齐次泊松改变的只是事件发生时刻的分布。复合泊松则是改变单次时间发生的影响大小(但仍然不随着时间变化)。
2.2. 过滤泊松过程的特征函数
因此,想要放松独立增量的条件,我们实际上就是让每次事件发生所产生的影响【随着时间而变化】。也就是我们希望分析下面的过滤泊松过程:
\[\begin{equation} Y(t)=\sum_{k=1}^{N(t)}X_k(t,\tau_k) \end{equation}\]其中,$\tau_k$ 是第 $k$ 个事件发生时的时间。由于现在事件的影响随着时间变化,因此这个事件的发生时刻也是特别重要的。我们假设 $X$ 和 $N(t)$ 是独立的,$X_k$ 是 i.i.d. 的随机变量。
我们考虑 $Y(t)$ 的特征函数:
\[\begin{equation} \begin{aligned} \phi_Y(\omega) &= \mathbb{E}\left[ \exp\left(j\omega Y(t)\right) \right]\\ &= \mathbb{E}\left[ \exp\left(j\omega \sum_{k=1}^{N(t)}X_k(t,\tau_k)\right) \right]\\ &= \mathbb{E}_{N(t),\tau}\left[ \mathbb{E}_{X}\left[ \exp\left(j\omega \sum_{k=1}^{n}X_k(t,\tau_k)\right) \mid N(t)=n, \tau_1,\dots,\tau_n \right] \right]\\ &= \mathbb{E}_{N(t),\tau}\left[ \prod_{k=1}^{N(t)} \mathbb{E}_{X}\left[ \exp\left(j\omega X_k(t,\tau_k)\right) \right] \right]\\ \end{aligned} \end{equation}\]
- 这里不用矩母函数是因为没法保证 $Y(t)$ 一定是取整数值,而矩母函数比较适合处理点过程。
- 需要指出,$Y(t)$ 中包含了三个随机因素:$N(t)$、$X_k$ 和 $\tau_k$,因此条件期望是一种很重要的工具。
我们记
\[\begin{equation} B(t,\tau_k) = \mathbb{E}_{X}\left[ \exp\left(j\omega X_k(t,\tau_k)\right) \right] \end{equation}\]注意,$B(t,\tau_k)$ 仍然包含随机因素 $\tau_k$。但由于 $X_k$ 是 i.i.d. 的随机变量,因此 $B(t,\tau_k)$ 与 $k$ 无关。
代回原式得
\[\begin{equation} \begin{aligned} \phi_Y(\omega) &= \mathbb{E}_{N(t),\tau}\left[ \prod_{k=1}^{N(t)} B(t,\tau_k) \right]\\ &= \mathbb{E}_{N(t)}\left[ \mathbb{E}_{\tau}\left[ \prod_{k=1}^{n} B(t,\tau_k) \mid N(t)=n \right] \right]\\ \end{aligned} \end{equation}\]上面我们已经证明了,当给定事件发生次数 $N(t)=n$ 时,事件发生时刻 $\tau_1,\dots,\tau_n$ 服从 $n$ 个均匀分布的顺序统计量,其概率密度由公式 \eqref{eq:T-t-distribution} 给出。
因此:
\[\begin{equation} \begin{aligned} \phi_Y(\omega) &= \mathbb{E}_{N(t)}\left[ \int_{0}^{t}\int_{0}^{\tau_n}\cdots\int_{0}^{\tau_2} \frac{n!}{t^n} \prod_{k=1}^{n}B(t,\tau_k) \mathrm{d}\tau_1\cdots\mathrm{d}\tau_n \mid N(t)=n \right]\\ \end{aligned} \end{equation}\]注意到这里的被积函数是一个关于 $\tau_1,\dots,\tau_n$ 的对称函数。根据公式 \eqref{eq:sym-integral},我们有:
\[\begin{equation} \begin{aligned} \phi_Y(\omega) &= \mathbb{E}_{N(t)}\left[ \int_{0}^{t}\int_{0}^{t}\cdots\int_{0}^{t} \frac{1}{t^n} \prod_{k=1}^{n}B(t,\tau_k) \mathrm{d}\tau_1\cdots\mathrm{d}\tau_n \mid N(t)=n \right]\\ &= \mathbb{E}_{N(t)}\left[ \frac{1}{t^n} \prod_{k=1}^{n} \int_{0}^{t} B(t,\tau_k) \mathrm{d}\tau_k \mid N(t)=n \right]\\ &= \mathbb{E}_{N(t)}\left[ \frac{1}{t^n} \left( \int_{0}^{t} B(t,\tau) \mathrm{d}\tau \right)^n \mid N(t)=n \right]\\ &= \mathbb{E}_{N(t)}\left[ \left( \frac{1}{t} \int_{0}^{t} B(t,\tau) \mathrm{d}\tau \right)^{N(t)} \right]\\ \end{aligned} \end{equation}\]这个形式正好是标准泊松过程的矩母函数。因此:
\[\begin{equation} \begin{aligned} \phi_Y(\omega) &= G_{N(t)} \left( \frac{1}{t} \int_{0}^{t} B(t,\tau) \mathrm{d}\tau \right)\\ &= \exp\left( \lambda t \left( \frac{1}{t} \int_{0}^{t} B(t,\tau) \mathrm{d}\tau -1 \right) \right)\\ &= \exp\left( \lambda \int_{0}^{t} (B(t,\tau)-1) \mathrm{d}\tau \right)\\ &= \exp\left( \lambda \int_{0}^{t} \left( \mathbb{E}_{X}\left[ \exp\left(j\omega X_1(t,\tau)\right) \right] -1 \right) \mathrm{d}\tau \right)\\ \end{aligned} \end{equation}\]我们来计算一下过滤泊松过程的均值:
\[\begin{equation} \begin{aligned} \mathbb{E}[Y(t)] &= \left. \frac{1}{j} \frac{\mathrm{d}}{\mathrm{d}\omega} \phi_Y(\omega) \right|_{\omega=0}\\ &= \frac{1}{j} \lambda \int_{0}^{t} \left( \left. \frac{\mathrm{d}}{\mathrm{d}\omega} \mathbb{E}_{X}\left[ \exp\left(j\omega X_1(t,\tau)\right) \right] -1 \right|_{\omega=0} \right) \mathrm{d}\tau \cdot\phi_Y(0)\\ &= \frac{1}{j} \lambda \int_{0}^{t} \left( \mathbb{E}_{X}\left[ j X_1(t,\tau) \right] \right) \mathrm{d}\tau\\ &= \lambda \int_{0}^{t} \mathbb{E}_{X}\left[ X_1(t,\tau) \right] \mathrm{d}\tau\\ \end{aligned} \end{equation}\]2.3. 过滤泊松过程的几个习题
2.3.1. 发车问题
设一个公交站在一段时间 $[0,T]$ 内要发 $n$ 趟车。每发一趟车,都会把当前站台上的所有乘客接走,假设乘客到达站台的过程是一个参数为 $\lambda$ 的泊松过程 $N(t)$。
我们需要构造一个最优的发车计划,使得所有乘客的总等待时间的均值最小。
由于每次发车都会把所有乘客接走,因此不同车次之间的情况是相互独立的。我们只需要考虑单次发车的情况。
考虑在任意一个长度为 $t$ 的时间段。在这段时间内,到达乘客的总等待时间为:
\[\begin{equation} W(t)=\sum_{k=1}^{N(t)}(t-\tau_k) \end{equation}\]代入过滤泊松过程的模型中,我们的响应函数
\[\begin{equation} X_k(t,\tau_k)=t-\tau_k \end{equation}\]因此,总等待时间的均值为:
\[\begin{equation} \begin{aligned} \mathbb{E}[W(t)] &= \lambda \int_{0}^{t} \mathbb{E}_{X}\left[ X_1(t,\tau) \right] \mathrm{d}\tau\\ &= \lambda \int_{0}^{t} \mathbb{E}_{X}\left[ t-\tau \right] \mathrm{d}\tau\\ &= \lambda \int_{0}^{t} (t-\tau) \mathrm{d}\tau\\ &= \frac{1}{2}\lambda t^2 \end{aligned} \end{equation}\]假设某一个发车计划 $t_1,\dots,t_n$,将 $[0,T]$ 切分为 $n$ 个时间段,每一段时间的长度为 $S_1,\dots,S_n$,且
\[\begin{equation} \sum_{k=1}^n S_k=T \end{equation}\]此时,所有乘客的总等待时间期望为:
\[\begin{equation} \begin{aligned} \mathbb{E}[W] &= \mathbb{E}\left[\sum_{k=1}^n W(S_k)\right]\\ &= \sum_{k=1}^n \mathbb{E}\left[W(S_k)\right]\\ &= \frac{\lambda}{2} \sum_{k=1}^n S_k^2\\ \end{aligned} \end{equation}\]因此,我们的优化问题可以转化为:
\[\begin{equation} \begin{aligned} &\min\quad \frac{\lambda}{2} \sum_{k=1}^n S_k^2\\ &\text{s.t.}\quad \sum_{k=1}^n S_k=T \end{aligned} \end{equation}\]这个优化问题的解是:
\[\begin{equation} S_1=\cdots=S_n=\frac{T}{n} \end{equation}\]即等间隔发车。
这个问题比较简单,其实有个更加简单的方法:
\[\begin{equation} \begin{aligned} \mathbb{E}[W(t)] &= \mathbb{E}\left[\sum_{k=1}^{N(t)} (t-\tau_k)\right]\\ &= \mathbb{E}\left[tN(t)\right] - \mathbb{E}\left[\sum_{k=1}^{N(t)} \tau_k\right]\\ &= \lambda t^2 - \mathbb{E}_{N(t)}\left[ \mathbb{E}_{\tau_k}\left[ \sum_{k=1}^{n} \tau_k \mid N(t)=n \right] \right]\\ \end{aligned} \end{equation}\]这里有个很巧妙的方法。我们已经知道在给定 $N(t)=n$ 的条件下,到达时间 $\tau_k$ 服从 $n$ 个 $U[0,t]$ 的顺序统计量。然而,我们这里将 $\tau_k$ 全部求和了,因此是否是排序的并没有影响。
这里可以类比普通数值的情况,排不排序对于求和结果没有影响。
但我们还是要着重强调,这里 $\tau_k$ 是一个随机变量,其顺序统计量并不是按照【大小】来排序,而是定义了全新的随机变量。
然而,即使在这种情况下,求和的结果仍然与排不排序无关。
因此,这里第二项的里层期望就直接等于 $n$ 个 $U[0,t]$ 的期望之和,即
\[\begin{equation} \begin{aligned} \mathbb{E}[W(t)] &= \lambda t^2 - \mathbb{E}_{N(t)}\left[ N(t)\cdot \frac{t}{2} \right]\\ &= \lambda t^2-\frac{1}{2}\lambda t^2\\ &= \frac{1}{2}\lambda t^2 \end{aligned} \end{equation}\]2.3.2. 公园内的平均人数
假设每天到达公园的游客是一个参数为 $\lambda$ 的泊松过程 $N(t)$。每个游客在公园中逗留的时间是一个独立同分布的随机变量,其概率密度为 $f(x)$。
我们希望研究在某一时刻公园内的平均人数。
考虑在 $t$ 时刻,公园内的游客数量为随机过程 $Y(t)$,其中:
\[\begin{equation} Y(t)= \sum_{k=1}^{N(t)} \mathbb{I}(t-\tau_k\leq z) \end{equation}\]其中,
\[\begin{equation} z\sim f(x) \end{equation}\]因此,平均人数为:
\[\begin{equation} \begin{aligned} \mathbb{E}[Y(t)] &= \lambda \int_{0}^{t} \mathbb{E}\left[ \mathbb{I}(t-\tau\leq z) \right] \mathrm{d}\tau\\ &= \lambda \int_{0}^{t} P(t-\tau\leq z) \mathrm{d}\tau\\ &= \lambda \int_{0}^{t} \int_{t-\tau}^{\infty} f(s) \mathrm{d}s \mathrm{d}\tau\\ \end{aligned} \end{equation}\]2.3.3. 排队问题
考虑一个交换结点,数据包以参数为 $\lambda$ 的泊松过程 $N(t)$ 到达。每个数据包到达以后就立刻(没有等待时间)被交换结点服务转发,服务时间是一个随机变量,其概率密度为 $f(x)$。我们希望考察某一个时间上交换结点内的数据包平均数量。
这道题和上面的公园内平均人数是一样的,因此我们不再重复求解。我们这里的目的是介绍排队论的符号体系。
在这套符号体系中总共有三个要素:
- 怎么来的(到达的时间间隔)
- 如果到达时间间隔服从指数分布(即泊松过程到达),则记这个间隔为 $M$ (Markovian);
- 否则,记这个间隔为 $G$ (General)。
- 怎么走的(服务时间)
- 同样地,按照服务时间是否服从指数分布,记为 $M$ 或 $G$。
- 服务体系中有多少资源(等待时间)
- 记为 $k$
这个三元组是一套描述排队问题的公用符号体系,是由英国学者 Kendall 提出的。
比如说,我们上面的交换结点问题和公园内平均人数问题,本质上都是 $M/G/\infty$ 的排队模型。这类问题都能够使用过滤泊松过程解决,其关键原因在于服务体系中的资源是无限的 ($k=\infty$)。如果 $k$ 是有限的,过滤泊松中 $X_k$ 就不再是 i.i.d. 的随机变量(因为来到之后不仅有服务时间,还有等待时间,而等待时间与前面到达的事件相关),整套体系就失效了。
为了解决 $k$ 有限的情况下的排队问题,我们就需要引入马尔可夫链。这就是下一篇的内容了。
Appendix
Apd.1. 公式 \eqref{eq:T-t-distribution} 是一个概率密度
我们来证明概率密度
\[\begin{equation} f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n)= \begin{cases} \frac{n!}{t^n},&0\leq x_1\leq x_2\leq\cdots\leq x_n\leq t\\ 0,&\text{otherwise} \end{cases} \end{equation}\]的积分是1。
直接积分
\[\begin{equation} \begin{aligned} &\quad\ \int_{0}^{t}\cdots \int_{0}^{t} f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n) \mathrm{d}x_1\cdots\mathrm{d}x_n\\ &= \int_{0}^{t}\cdots \int_{0}^{t} \mathbb{I}(0\leq x_1\leq x_2\leq\cdots\leq x_n\leq t) \frac{n!}{t^n} \mathrm{d}x_1\cdots\mathrm{d}x_n\\ &= \frac{n!}{t^n} \int_{0}^{t}\int_{0}^{x_n}\cdots \int_{0}^{x_3}\int_{0}^{x_2} \mathrm{d}x_1\cdots\mathrm{d}x_n\\ &= \frac{n!}{t^n} \int_{0}^{t}\int_{0}^{x_n}\cdots \int_{0}^{x_3} x_2 \mathrm{d}x_2\cdots\mathrm{d}x_n\\ &= \frac{n!}{t^n} \frac{1}{2!} \int_{0}^{t}\int_{0}^{x_n}\cdots \int_{0}^{x_4} x_3^2 \mathrm{d}x_3\cdots\mathrm{d}x_n\\ &= \frac{n!}{t^n} \frac{1}{3!} \int_{0}^{t}\int_{0}^{x_n}\cdots \int_{0}^{x_5} x_4^3 \mathrm{d}x_4\cdots\mathrm{d}x_n\\ &= \cdots\\ &= \frac{n!}{t^n} \frac{1}{(n-1)!} \int_{0}^{t} x_n^{n-1} \mathrm{d}x_n\\ &=1 \end{aligned} \end{equation}\]当然,也可以这么写:
\[\begin{equation} \begin{aligned} &\quad\ \int_{0}^{t}\cdots \int_{0}^{t} f_{S_1,\dots,S_n\mid N(t)=n}(x_1,\dots,x_n) \mathrm{d}x_1\cdots\mathrm{d}x_n\\ &= \int_{0}^{t}\cdots \int_{0}^{t} \mathbb{I}(0\leq x_1\leq x_2\leq\cdots\leq x_n\leq t) \frac{n!}{t^n} \mathrm{d}x_1\cdots\mathrm{d}x_n\\ &= \frac{n!}{t^n} \int_{0}^{t}\int_{x_1}^{t}\cdots\int_{x_{n-2}}^{t}\int_{x_{n-1}}^{t} \mathrm{d}x_n\cdots\mathrm{d}x_1 \end{aligned} \end{equation}\]有个口诀就是【要么顶天要么立地】可以帮助记忆。
对称函数积分
上面的积分能做是因为被积函数是一个常数。但凡被积函数不是常数,这个积分都非常难算。
下面,我们来介绍一种积分技巧,即对称函数积分。
对于函数 $g(x_1,\dots,x_n)$,我们称 $g$ 是对称函数,当且仅当对于对称群中的任意排列 $\sigma(1),\dots,\sigma(n)$,都不改变函数值,即
\[\begin{equation} g(x_1,\dots,x_n)=g(x_{\sigma(1)},\dots,x_{\sigma(n)}) \end{equation}\]对称函数的积分满足如下性质:
\[\begin{equation} \begin{aligned} \int_{0}^{t}\int_{0}^{x_n}\cdots \int_{0}^{x_2} g(x_1,\dots,x_n) \mathrm{d}x_1\cdots\mathrm{d}x_n &= \frac{1}{n!} \int_{0}^{t}\cdots \int_{0}^{t} g(x_1,\dots,x_n) \mathrm{d}x_1\cdots\mathrm{d}x_n \end{aligned} \label{eq:sym-integral} \end{equation}\]证明是显然的。
右侧的积分区域是一个 $n$ 维超立方体。这个超立方体中,正好可以被划分为多个子区域,每个子区域都类似左侧的积分区域,即:
\[\begin{equation} 0\leq \sigma(1)\leq \sigma(2)\leq\cdots\leq \sigma(n)\leq t \end{equation}\]由于对称群中正好有 $n!$ 个排列,因此这样的子区域正好有 $n!$ 个。
又根据对称性,对称函数在所有子区域上的积分都是相等的。因此,每个子区域上的积分正好是超立方体上的积分的 $1/n!$。($n$ 维标准单纯形的体积是 $1/n!$)
Apd.2. 顺序统计量的联合概率密度
现在我们来计算顺序统计量的联合概率密度。
首先,我们来考察一下 $X_{(n)}=\max(X_1,\dots,X_n)$ 的概率分布。
\[\begin{equation} \begin{aligned} F_{X_{(n)}}(x) &= P(X_{(n)}\leq x)\\ &= P(\max(X_1,\dots,X_n)\leq x)\\ &= P(X_1\leq x, \dots, X_n\leq x)\\ &= \prod_{k=1}^n P(X_k\leq x)\\ &= [F_{X_1}(x)]^n \end{aligned} \end{equation}\]因此,其概率密度为:
\[\begin{equation} \begin{aligned} f_{X_{(n)}}(x) &= \frac{\mathrm{d}}{\mathrm{d}x} [F_{X_1}(x)]^n\\ &= n[F_{X_1}(x)]^{n-1}f_{X_1}(x) \end{aligned} \end{equation}\]同理,$X_{(1)}=\min(X_1,\dots,X_n)$ 的概率分布为:
\[\begin{equation} \begin{aligned} F_{X_{(1)}}(x) &= P(X_{(1)}\leq x)\\ &= P(\min(X_1,\dots,X_n)\leq x)\\ &= 1-P(\min(X_1,\dots,X_n)\gt x)\\ &= 1-P(X_1\gt x, \dots, X_n\gt x)\\ &= 1-\prod_{k=1}^n P(X_k\gt x)\\ &= 1-(1-F_{X_1}(x))^n \end{aligned} \end{equation}\]因此其概率密度为:
\[\begin{equation} \begin{aligned} f_{X_{(n)}}(x) &= \frac{\mathrm{d}}{\mathrm{d}x} 1-(1-F_{X_1}(x))^n\\ &= n[1-F_{X_1}(x)]^{n-1}f_{X_1}(x) \end{aligned} \end{equation}\]一头一尾的都好做,比较难做的是中间的情况。我们来考察 $X_{(k)}$ 的概率分布。
\[\begin{equation} \begin{aligned} F_{X_{(k)}}(x) &= P(X_{(k)}\leq x) \end{aligned} \end{equation}\]这个时候做概率转换很难做。此时,我们考虑使用微元法,让 $X_{k}$ 落在某个微元 $(x,x+\Delta x]$ 中,在前面还有 $k-1$ 个元素,后面还有 $n-k$ 个元素。
注意,这里的表述是前面还有 $k-1$ 个元素,并不一定就是 $X_{1},\dots,X_{k-1}$,而是任取 $k-1$ 个元素。同理,后面也不一定是 $X_{k+1},\dots,X_{n}$。这里的情况总共有 $\binom{n}{k-1}\binom{n-k+1}{n-k}$ 种。
因此,我们有
\[\begin{equation} \begin{aligned} &\quad\ f_{X_{(k)}}(x)\\ &= \lim_{\Delta x\to 0} \frac{1}{\Delta x} \binom{n}{k-1}\binom{n-k+1}{n-k} P(X_{1},\dots,X_{k-1}\leq x, X_{k}\in (x,x+\Delta x], X_{k+1},\dots,X_{n}\gt x+\Delta x)\\ &= \lim_{\Delta x\to 0} \frac{1}{\Delta x} \binom{n}{k-1}\binom{n-k+1}{n-k} (F_{X_1}(x))^{k-1} (F_{X_1}(x+\Delta x)-F_{X_1}(x)) (1-F_{X_1}(x+\Delta x))^{n-k}\\ &= \binom{n}{k-1}\binom{n-k+1}{n-k} (F_{X_1}(x))^{k-1} f_{X_1}(x) (1-F_{X_1}(x))^{n-k} \end{aligned} \end{equation}\]这种形式的结果远远不止求一维概率,我们可以直接写出更高维概率分布的密度。比如说:
\[\begin{equation} \begin{aligned} &\quad\ f_{X_{(k)},X_{(m)}}(x_k,x_m)\\ &= \underbrace{\binom{n}{k-1}}_{小于 x_k} \underbrace{\binom{n-k+1}{m-k-1}}_{x_k到x_m} \underbrace{\binom{n-m+2}{n-m}}_{大于 x_m} \underbrace{\binom{2}{1}}_{x_k 和 x_m}\\ &\quad\ \underbrace{(F_{X_1}(x_k))^{k-1}}_{小于 x_k} \underbrace{(F_{X_1}(x_m)-F_{X_1}(x_k))^{m-k-1}}_{x_k到x_m} \underbrace{(1-F_{X_1}(x_m))^{n-m}}_{大于 x_m}\\ &\quad\ f_{X_1}(x_k) f_{X_1}(x_m) \end{aligned} \end{equation}\]甚至,我们可以直接写出 $n$ 维的联合概率密度。此时,所有随机变量都处于某个微元之中,我们甚至更好写:
\[\begin{equation} \begin{aligned} f_{X_{(1)},\dots,X_{(n)}}(x_1,\dots,x_n) &= \binom{n}{1}\binom{n-1}{1}\cdots\binom{2}{1}\binom{1}{1} f_{X_1}(x_1)f_{X_1}(x_2)\cdots f_{X_1}(x_n)\\ &= n!\prod_{k=1}^n f_{X_1}(x_k) \end{aligned} \end{equation}\]当然,我们也不能忘了顺序的问题。所以实际上的联合概率密度为:
\[\begin{equation} f_{X_{(1)},\dots,X_{(n)}}(x_1,\dots,x_n)= \begin{cases} n!\prod_{k=1}^n f_{X_1}(x_k),& x_1\leq x_2\leq\dots\leq x_n\\ 0,& \text{otherwise} \end{cases} \end{equation}\]