- 统一精排阶段的特征交叉和序列建模
- 多目标优化对齐
- 利用PRM监督生成式推荐模型
- 个性化搜索中的知识-动作对齐
- 生成式推荐系统中的预测解码加速

1. Motivation
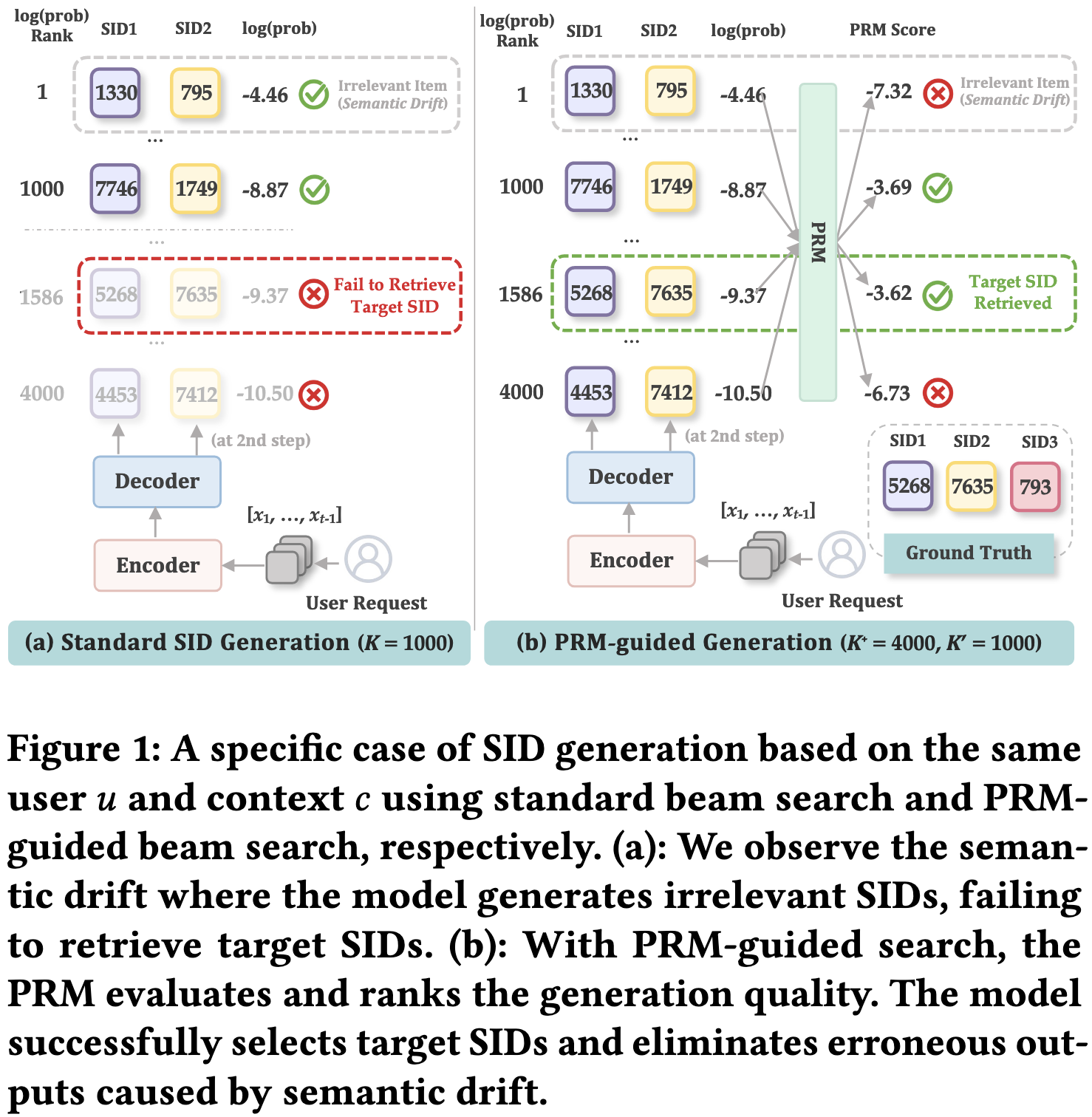
生成式推荐系统需要将item转变为语义ID (Semantic ID, SID),以此把next-item prediction的任务转变为和LLM相同的next-token prediction任务。
早期的SID编码方法一般是层次化量化(如RQ-VAE、Residual K-means等),将item的多模态语义embedding离散化为若干个token组成的序列,其中,靠前的token用于编码粗粒度语义和共性信息(如“电子产品”类),而靠后的token则用于编码细粒度细节和个性化信息(如“索尼耳机”)。
作者提出了这种语义编码的一个核心挑战:语义漂移(Semantic Drift),即由于误差累积导致生成的轨迹逐渐偏离用户的真实意图。
根因
作者认为,产生语义漂移的根本原因在于【曝光偏差】(Exposure Bias),即模型在训练和推理阶段存在不一致性:
- 在训练阶段,模型会根据真实的交互数据来预测下一个token。
- 在推理阶段,模型则需要自回归地根据之前生成的token来预测下一个token。
也就是说,模型在训练阶段从没有接触过自身预测错误导致的误差累积。
机制
这种曝光偏差的问题在SID的编码方式中会产生更加严重的问题。一旦靠前的token预测错误(如从“电子产品”类错误预测为“图书”类),后续所有细粒度预测都只能在错误的语义子空间中进行,导致推荐结果与用户真实意图偏离。
后果
这种语义偏移会导致模型在遇到OOD状态时,倾向于回归到训练数据的分布,加剧流行度偏差,生成长尾物品的能力受损。
语义漂移问题同样也会出现在LLM中,特别是在一些需要长CoT的任务上(比如数学推理、代码生成)。在这些问题中,中间步骤的一个小错误往往会导致最终的结果出错。为此,近期的研究提出使用过程奖励模型 (Process Reward Model, PRM) 来对生成的轨迹进行打分,以此缓解结果奖励模型 (Outcome Reward Model, ORM) 的奖励稀疏问题。
2. Methodology
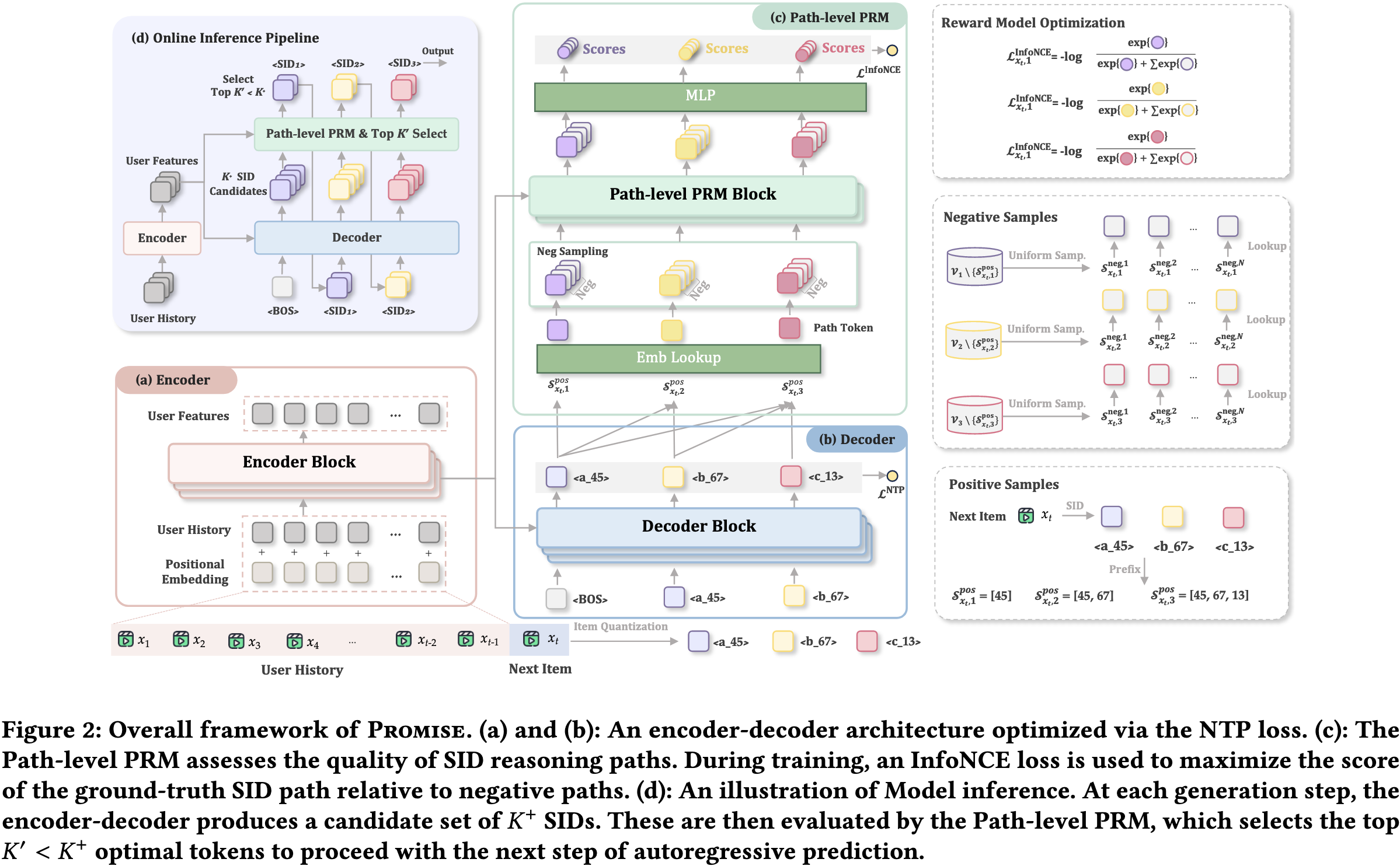
2.1. Overview
类比LLM中的做法,作者提出了PROMISE (Process Reward Model Unlock Test-Time Scaling Laws in Generative Recommendations),这是一个将过程奖励模型无缝集成到生成式推荐系统中的框架。PROMISE中包含两大组件:
- 路径级的PRM:和推荐模型一起训练,用于为中间推理步骤打分。
- PRM引导的Beam-Search策略:在推理阶段利用PRM的打分,对低质量的分支尽快剪枝,从而尽早暴露高质量的语义子空间。
更重要的是,作者发现PROMISE框架可以让生成式推荐系统具备test-time scaling的能力:当增加推理时的搜索宽度,小模型的表现甚至能够超过大模型。
2.2. Path-Level PRM
作者提出了一个轻量级、低延迟的PRM模型来为中间推理步骤打分。这个PRM是和推荐模型一起训练的,但是使用的训练数据则是采样生成的正负样本,因此避免了曝光偏差的问题。
2.2.1. 训练数据采样
正样本
假设ground-truth item $x_t$ 被语义编码器编码为 $[s_t^1, s_t^2, \dots, s_t^d]$,其中 $d$ 是码本长度。
由于生成式推荐系统是逐个token地进行解码,因此想要正确地生成深度为 $d$ 的token $s_t^d$,需要模型能够正确地预测出前面的所有token $[s_t^1, s_t^2, \dots, s_t^{d-1}]$。因此,一条长度为 $b$ 的正样本路径为:
\[\begin{equation} \mathcal{S}_{x_t,b}^{\text{pos}} = \left[ s_t^1, s_t^2, \dots, s_t^b \right],b\le d \end{equation}\]因此,$x_t$ 的所有正样本路径为 $\lbrace \mathcal{S}_{x_t,b}^{\text{pos}} \rbrace _{b=1}^d$。
负样本
令 $\mathcal{V}_{b}$ 表示长度为 $b$ 的有效路径集合,有效路径是指能够对应上某个真实item的SID序列。
对于 $x_t$ 的一条的正样本路径 $\mathcal{S}_{x_t,b}^{\text{pos}}\in \mathcal{V}_b$,我们在 $\mathcal{V}_b$ 剩下的路径中均匀采样 $N$ 条路径作为负样本集:
\[\begin{equation} \mathcal{N}_{x_t,b}= \lbrace \mathcal{S}^{\text{neg}}_{i}\mid \mathcal{S}^{\text{neg}}_{i}\sim\text{Uniform}(\mathcal{V}_b\setminus\lbrace\mathcal{S}_{x_t,b}^{\text{pos}}\rbrace), i=1,2,\dots,N \rbrace \end{equation}\]2.2.2. 训练PRM
PRM的任务是给定user $u$、context $c$ 以及一条长度为 $b$ 的路径,预测该路径和user的相关性分数:
\[\begin{equation} \mathcal{F}:(u,c,[s_1,s_2,\dots,s_b])\mapsto y\in\mathbb{R} \end{equation}\]作者使用层级InfoNCE来训练PRM:
\[\begin{equation} \mathcal{L}^{\text{InfoNCE}}_{x_t,b} = -\log\left(\frac{\exp(\mathcal{F}(\mathcal{S}_{x_t,b}^{\text{pos}}))} {\exp(\mathcal{F}(\mathcal{S}_{x_t,b}^{\text{pos}}))+\sum_{i=1}^N\exp(\mathcal{F}(\mathcal{S}^{\text{neg}}_{i}))}\right) \end{equation}\]这个PRM和推荐模型共同训练:
\[\begin{equation} \mathcal{L}^{\text{total}}_{x_t,b} = \mathcal{L}^{\text{NTP}}_{x_t}+ \sum_{b=1}^d\mathcal{L}^{\text{InfoNCE}}_{x_t,b} \end{equation}\]其中,$\mathcal{L}^{\text{NTP}}_{x_t}$ 是主干网络的训练loss:
\[\begin{equation} \mathcal{L}^{\text{NTP}}_{x_t}= -\sum_{b=1}^d\log p_{\theta}(s_t^b\mid s_t^1,\dots,s_t^{b-1},x_1,\dots,x_{t-1},u,c) \end{equation}\]2.2.3. PRM的架构
为了在工业推荐场景下使用,作者设计了一个轻量级、低延迟的PRM架构。
PRM复用主干网络Encoder侧输出的用户表征 $E^{(L)}$ 作为attention的key和value,query则根据路径 $[s_1,s_2,\dots,s_b]$ 从embedding表中映射:
\[\begin{equation} \begin{aligned} P_{\mathcal{S}}^{(0)}&=\text{Emb}([s_1,s_2,\dots,s_b])\\ P_{\mathcal{S}}^{(i)'}&=P_{\mathcal{S}}^{(i-1)}+\text{CrossAttn}(P_{\mathcal{S}}^{(i-1)},E^{(L)},E^{(L)})\\ P_{\mathcal{S}}^{(i)}&=P_{\mathcal{S}}^{(i)'}+\text{FFN}(\text{RMSNorm}(P_{\mathcal{S}}^{(i)'})) \end{aligned} \end{equation}\]最后使用一个MLP输出分数:
\[\begin{equation} y_{\mathcal{S}}=\text{MLP}(P_{\mathcal{S}}^{(F)}) \end{equation}\]实际上作者取 $F=1$,即单层attention。
2.3. 推理策略

现代LLM表现出很好的test-time scaling的能力,即当增加推理时的搜索宽度,小模型的表现甚至能够超过大模型。借助上面的PRM,作者提出通过增加推理时candidate的数量,同样也可以让生成式推荐系统具备test-time scaling的能力。
在传统的生成式推荐系统中,解码阶段使用固定beam-size的beam-search来生成token:在计算完logits之后,仅保留 top-$K$ 的token作为下一个步解码的candidate。虽然增大 $K$ 能够让模型考虑更多的SID,但同时也让计算量线性增加,难以做到test-time scaling。
然而,PRM可以用较少的计算量来为每个candidate路径进行打分,因此我们可以让主干模型生成更多的candidates ($K^+\gg K$),然后再用PRM对这 $K^+$ 个candidates进行筛选,仅保留 top-$K$ 个路径。因此,PROMISE框架可以在仅增加极少计算量的情况下,实现test-time scaling的能力。
3. Experiments
3.1. 离线实验
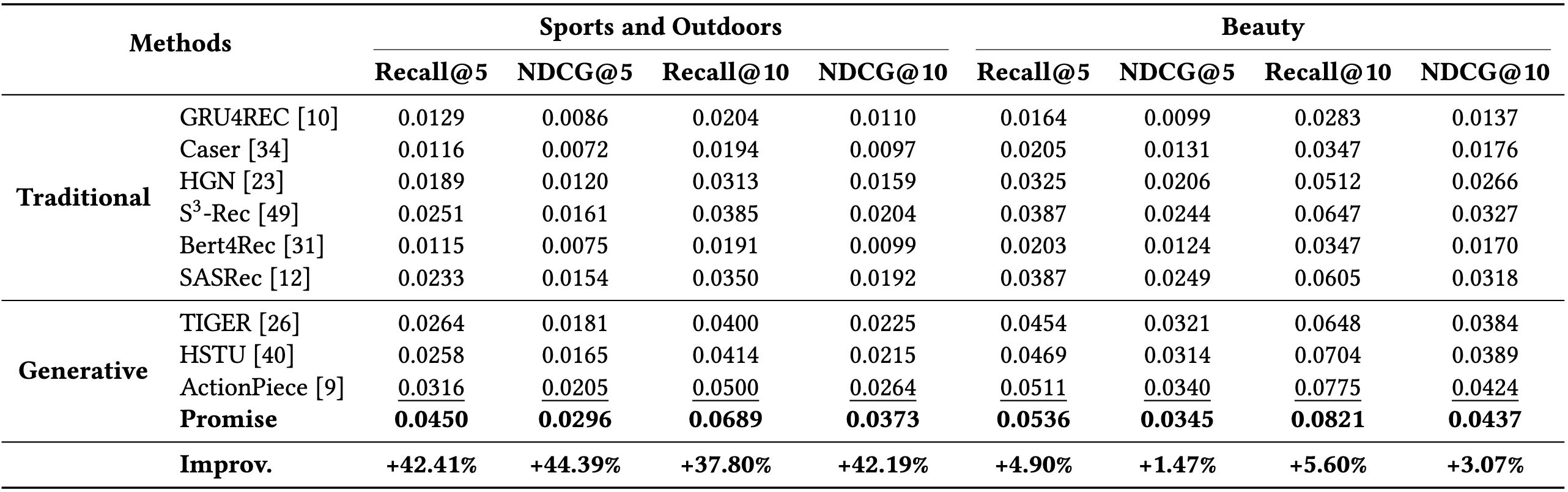
公开数据集
工业数据集
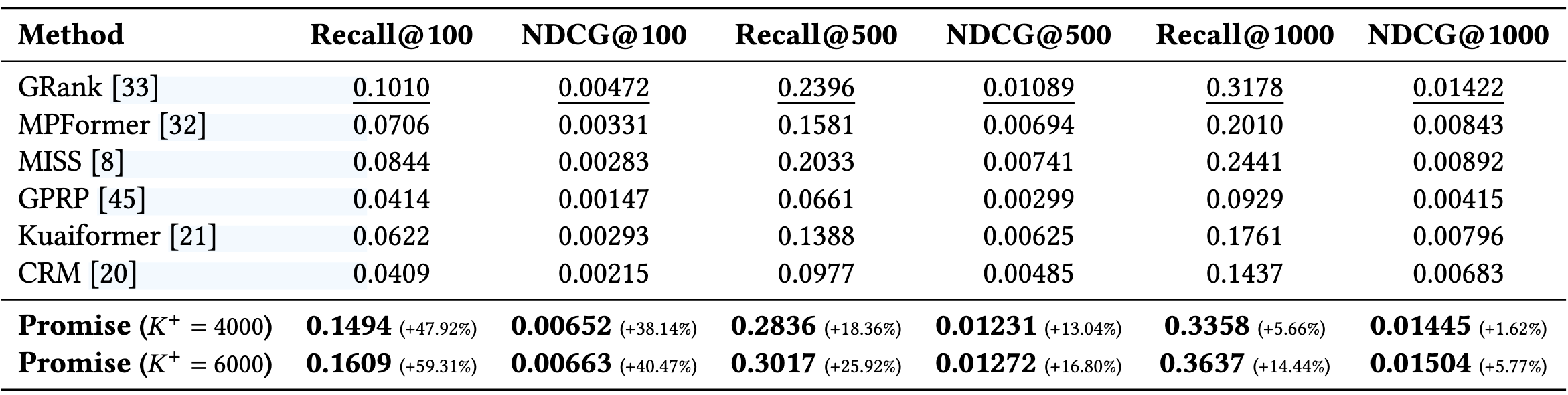
提升都非常非常大,甚至能到40%
3.2. 线上A/B

3.3. Test-Time Scaling
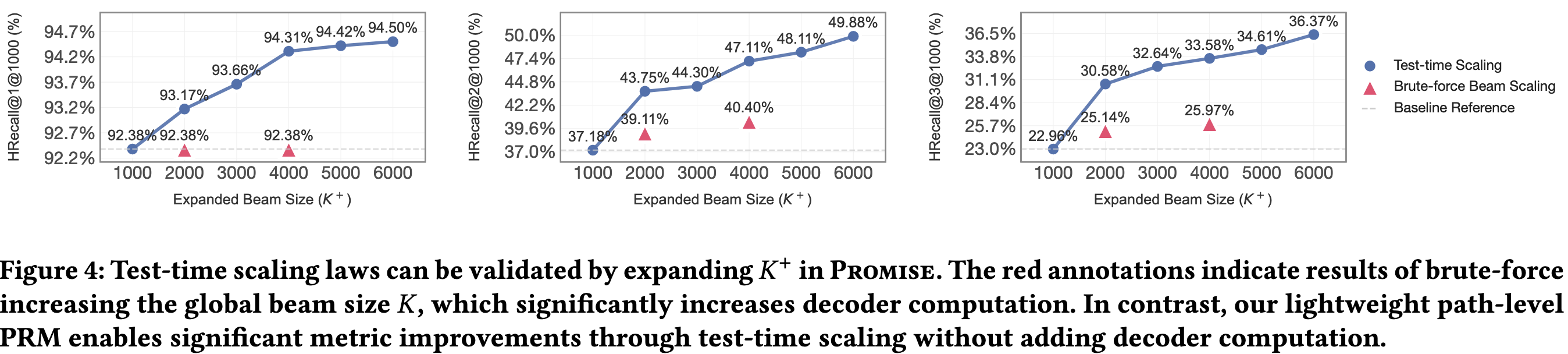
随着解码宽度 $K^+$ 的增加,PROMISE能够稳定提高性能,并远超传统的beam-search方法。