- 统一精排阶段的特征交叉和序列建模
- 多目标优化对齐
- 利用PRM监督生成式推荐模型
- 个性化搜索中的知识-动作对齐
- 生成式推荐系统中的预测解码加速
1. Preliminary: LLM 中的 Speculative Decoding
在介绍生成式推荐中的预测解码之前,我们首先回顾 LLM 中 Speculative Decoding 的基本原理。
1.1. 标准预测解码算法
Speculative Decoding 的核心思想是利用一个小模型 (drafting model) 快速生成候选 token 序列,然后用大模型 (target model) 并行验证这些候选。
给定前缀 $x_{\lt t}$,Speculative Decoding 的一个 block 要做下面的操作:
Algorithm 1: (Speculative Decoding)
-
Drafting model $q$ 自回归生成 $K$ 个 draft token
\[\begin{equation} y_k\sim q\left(\cdot\mid x_{\lt t},y_{\lt k}\right) \end{equation}\] -
Target model $p$ 并行计算所有 draft token 的概率:
\[\begin{equation} p_k(\cdot)=p\left(\cdot\mid x_{\lt t},y_{\lt k}\right) \end{equation}\] -
对于每个 draft token $y_k$,以概率
\[\begin{equation} \alpha_k(y_k)=\min\left(1, \frac{p_k(y_k)}{q_k(y_k)}\right) \end{equation}\]接受它。
-
若第一个被拒绝的token是 $y_j$,$j\in{1,\dots,K}$,则从残差分布中采样一个 token
\[\begin{equation} z\sim r_j(v)=\frac{\max\left(p_j(v)-q_j(v),0\right)}{\sum_u \max\left(p_u(v)-q_u(v),0\right)} \end{equation}\]替换 $y_j$,并终止当前 block,返回 $\left[ y_1,\dots,y_{j-1},z \right]$。
-
若全部 $K$ 个 token 都被接受,则从 target model 中额外采样一个token
\[\begin{equation} z\sim p\left(\cdot\mid x_{\lt t},y_{\lt K+1}\right) \end{equation}\]返回 $\left[ y_1,\dots,y_{K},z \right]$。
1.2. 输出分布不变性
预测解码的核心在于接受‑拒绝采样机制。由于 target model 可以并行验证所有候选 token,因此使用预测解码可以大幅度减少串行调用的次数。更重要的是,我们可以在数学上证明最终的输出分布和只用 target model 逐词生成完全一样,不会降低生成质量。
Theorem 1(Speculative Decoding 的分布一致性) 设 $X_1, X_2, \dots$ 为通过 Speculative Decoding 生成的序列,则对任意序列 $x_{1:n} $,有:
\[\begin{equation} \Pr(X_{1:n} = x_{1:n}) = \prod_{t=1}^n p(x_t \mid x_{<t}) \end{equation}\]定理的证明见附录1。
1.3. 加速比分析
我们来分析 Speculative Decoding 的加速比。约定下面的符号含义:
- block 大小为 $K$
- target 单次 forward 成本为 $C_t$
- draft 每生成 1 个 token 的成本为 $C_d$
- 第 $i$ 个 token 的接受率为 $\alpha_i$
则一个 block 的成本为
\[\begin{equation} C_{\text{block}} = K C_d + C_t \end{equation}\]平均输出 token 数为
\[\begin{equation} \mathbb{E}[L] = 1 + \sum_{i=1}^K \alpha_i \end{equation}\]因此,单位 token 的平均成本为
\[\begin{equation} \bar{C}_{\text{SD}} = \frac{K C_d + C_t}{1 + \sum_{i=1}^K \alpha_i} \end{equation}\]因此加速比为
\[\begin{equation} \begin{aligned} \mathrm{Speedup} &= \frac{C_t}{\bar{C}_{\text{SD}}}\\ &= \frac{1 + \sum_{i=1}^K \alpha_i}{1 + \rho K} \end{aligned} \end{equation}\]其中,$\rho = C_d/C_t$ 表示 draft model 的相对成本。
在均匀接受率 $\alpha_i \approx \alpha$ 的情况下,
\[\begin{equation} \mathrm{Speedup} \approx \frac{1 + \alpha K}{1 + \rho K}. \end{equation}\]该结果表明,加速效果由接受率 $\alpha$ 与 draft 相对成本 $\rho$ 共同决定,而非仅由 block size 控制。当且仅当 $\alpha > \rho$ 时,Speculative Decoding 才能带来实际加速。
1.4. 关键洞察
从上述分析可以得到几个重要洞察:
-
无损加速:Speculative decoding 不会改变 target model 的输出分布,因此不会影响生成质量。这是通过精心设计的接受 - 拒绝机制保证的。
-
接受率是关键:加速效果取决于 drafter 和 target 之间的分布相似度。分布越接近,接受率越高,加速效果越好。
-
Drafter 的选择:理想的 drafter 应该:
- 输出分布与 target 高度对齐(高接受率)
- 推理速度远快于 target(低 drafting 开销)
- 易于训练和维护(低工程成本)
这些洞察为后续介绍生成式推荐中的预测解码方法奠定了理论基础。
2. Motivation
2.1. 生成式推荐的推理瓶颈
生成式推荐将物品编码为离散的语义 ID,将 next-item prediction 任务转化为类似 LLM 的 next-token prediction 任务。然而,这种自回归的解码方式在工业部署中面临严重的推理延迟问题。
典型的 GR 部署包含三个阶段:(1) 物品 tokenization、(2) LLM 训练、(3) LLM serving。其中 serving 阶段的解码延迟是主要瓶颈。在工业级推荐场景中,核心服务要求响应时间小于 30 毫秒,但当前 GR 方案的延迟超过 1 秒。
解码延迟主要来源于 beam search 过程中的重复 LLM 调用。对于 beam size 为 $K$,语义 ID 长度为 $L$ 的场景,LLM 需要被调用 $K \times (L-1)$ 次。即使使用 KV-Cache 优化,解码阶段仍占总推理时间的 60% 以上。
2.2. 生成式推荐中预测解码的独特挑战
将 Speculative Decoding 应用于生成式推荐系统面临一些特有的挑战:
- Top-K 序列生成:推荐系统需要生成 top-K 个物品(即 K 个不同的 token 序列)作为推荐列表,而非一个 next-token。
- 严格验证要求:在 beam search 中,所有 top-K 序列都需要在每一步被成功 draft,验证条件更加严格。
- 归纳式推荐:传统 GR 模型只能在训练时见过的物品中生成推荐,无法推荐新物品。
近期多项工作针对这些问题提出了创新解决方案。本文系统介绍四项代表性工作:AtSpeed (ICLR’25)、LASER (SIGIR’25)、NEZHA (WWW’26) 和 SpecGR (AAAI’26)。
3. AtSpeed (ICLR’25)
📖 Efficient Inference for Large Language Model-based Generative Recommendation
🔗 paper: https://arxiv.org/abs/2410.05165
🔗 code: https://github.com/Linxyhaha/AtSpeed
3.1. Motivation
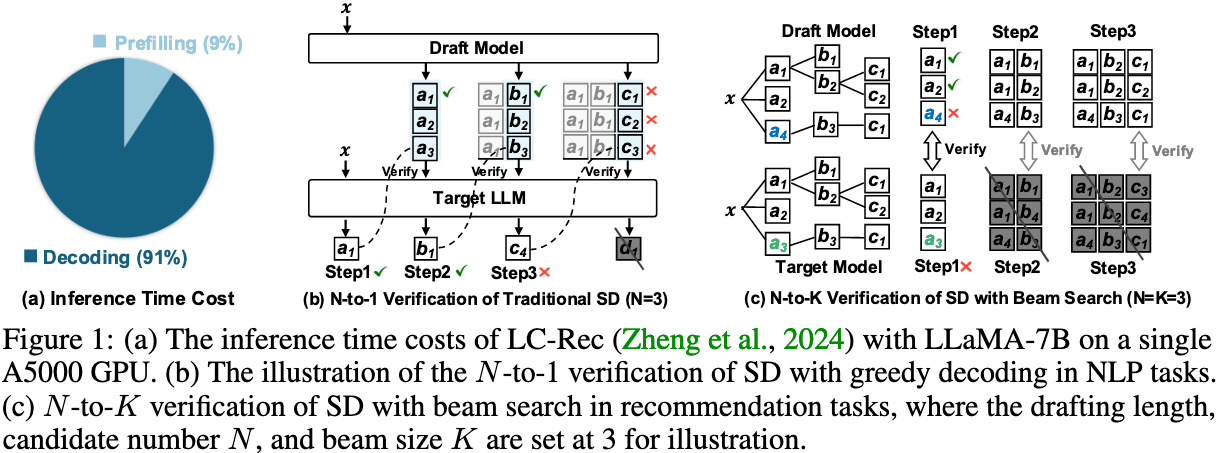
AtSpeed 指出生成式推荐与传统的 NLP 任务存在一个本质不同,导致直接应用传统 Speculative Decoding (SD) 不可行:
- N 对 1 验证 (NLP):在大多数 NLP 任务中,SD 旨在每一步接受 N 个 draft token 中的一个,仅生成一个输出序列。
- N 对 K 验证 (GR):GR 任务则需要通过 beam search 生成包含 K 个 item 的序列(即 K 个不同的 token 序列)。因此,在 GR 任务中 SD 想要成功解码一步,就需要让 draft model 生成的 N 个 item 中包含这 K 个真实 item。只要少了任意一个,整个推测步骤就会失败。这种 N 对 K 验证比 N 对 1 验证 要困难得多。
3.2. Methodology
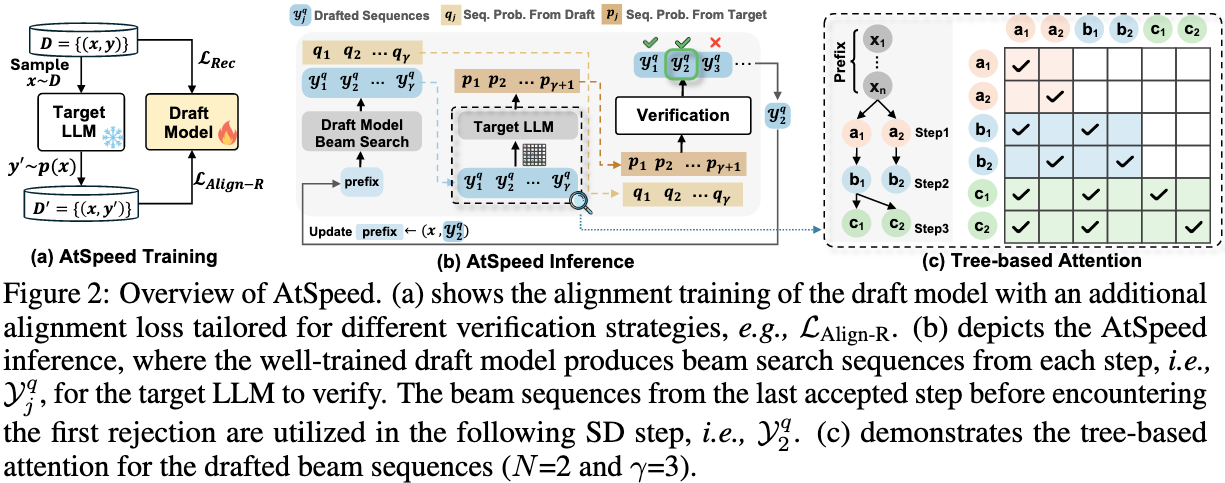
作者提出了 AtSpeed 框架,这是一个专门为通过改进的推测解码来加速基于LLM的生成式推荐而设计的对齐框架。该框架解决了两个关键策略:增强 draft 与 target 的对齐,以及放宽验证过程。
3.2.1. AtSpeed-S: 严格的 Top-K 验证
作者提出了 AtSpeed-S 优化目标,用于优化草稿模型,以最大化 target model 的生成的所有 Top-K 序列(真实值)都包含于 draft 中的概率。对齐损失中包含两个部分:
\[\begin{equation} \mathcal{L}_{\mathrm{Align-S}} = \mathrm{RKLD}(q\| p) + \mathrm{DensityReg}(q) \end{equation}\]其中,第一项是优化 draft $q$ 与 target $p$ 之间逆 KL 散度,鼓励二者的分布对齐。第二项是密度正则化项,将 $q$ 的概率质量集中在真实的 Top-K 序列周围。
最终,draft model 的训练目标为:
\[\begin{equation} \mathcal{L}_{\mathrm{AtSpeed-S}}=\alpha \mathcal{L}_{\mathrm{Align-S}} + (1-\alpha) \mathcal{L}_{\mathrm{Rec}} \end{equation}\]其中,$\mathcal{L}_{\mathrm{Rec}}$ 是标准的生成式推荐损失。
3.2.2. AtSpeed-R:宽松的采样验证
AtSpeed-R 则引入了一种更灵活的验证策略,允许非 Top-K 序列以一定概率方式被接受:
- 如果 $p(y) \geq q(y)$,则接受 draft sequence $y$。
- 否则,$y$ 以概率 $1-p(y)/q(y)$ 被拒绝。
这种宽松的方法最大化了步骤接受率:
\[\begin{equation} \begin{aligned} \beta &= \prod_K \mathbb{E}_{y\sim q(y)} \begin{cases} 1,&q(y)\leq p(y)\\ \frac{p(y)}{q(y)},&q(y)>p(y) \end{cases}\\ &= \prod_K \mathbb{E}_{y\sim q(y)}\min\left(1,\frac{p(y)}{q(y)}\right)\\ &= \prod_K 1-\mathrm{TVD}(p,q) \end{aligned} \end{equation}\]其中,$\mathrm{TVD}(p,q)$ 是分布 $p$ 和 $q$ 之间的 TVD 距离
\[\begin{equation} \begin{aligned} \mathrm{TVD}(p,q) &= \mathbb{E}_{y\sim p(y)}\vert q(y)-M(y)\vert\\ M(y)&=\frac{p(y)+q(y)}{2} \end{aligned} \end{equation}\]AtSpeed-R 的优化目标是最大化接受率 $\beta$。这等价于最小化 target 和 draft 之间的 TVD 距离:
\[\begin{equation} \mathcal{L}_{\mathrm{Align-R}} = \frac{1}{\vert y\vert} \sum_{t=1}^K \mathrm{TVD}\left( p(\cdot\mid x,y_{\lt t}), q(\cdot\mid x,y_{\lt t}) \right) \end{equation}\]3.3. Experiments
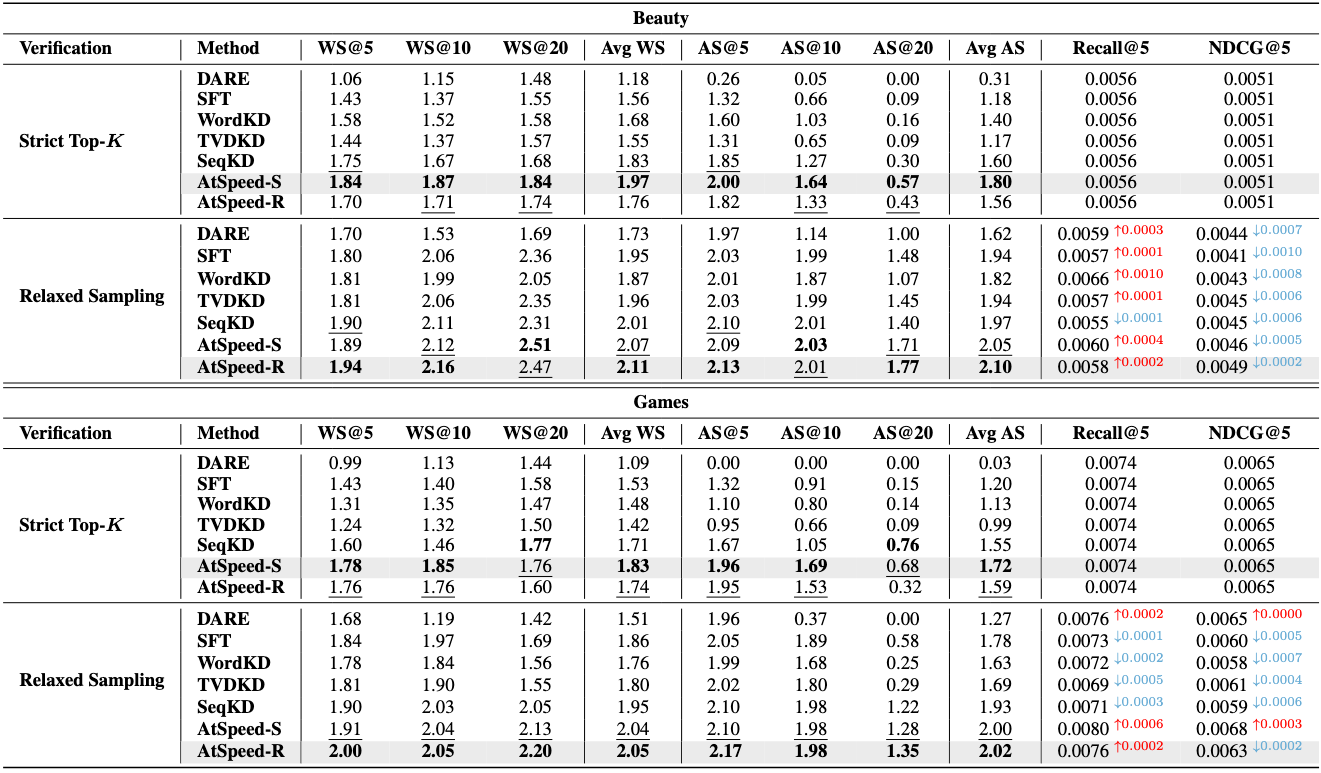
作者在 Amazon Beauty 和 Games 数据集上评估了 AtSpeed,使用 LLaMA-7B 作为 target model,LLaMA-68M 作为 draft model。
结果表明,在保持推荐质量的同时,AtSpeed 在不同的验证策略下实现了显著的加速:
- AtSpeed-S:在Beauty上实现1.97倍加速,在Games上实现1.83倍加速,精度无损
- AtSpeed-R:在Beauty上实现2.11倍加速,在Games上实现2.05倍加速,精度损失最小
松弛验证策略通常优于严格验证,因为它允许接受高概率的非Top-K序列,从而在保持输出分布保真度的同时提高接受率。
4. LASER (SIGIR’25)
📖 Efficiency Unleashed: Inference Acceleration for LLM-based Recommender Systems with Speculative Decoding
🔗 paper: https://arxiv.org/abs/2408.05676
🔗 code: https://github.com/YunjiaXi/LASER
4.1. Motivation
将LLM集成到推荐系统中已成为一个有前景的研究方向,利用其庞大的知识和推理能力来生成增强的用户画像、物品描述和解释性内容。然而,LLM 的直接实时部署在商业环境中面临严峻的延迟限制,通常要求数十亿用户和物品的响应时间保持在100毫秒以内。
因此,业界倾向于将 LLM 离线用作“特征增强器”——生成增强知识,然后将其整合到传统的、高效的推荐模型中。虽然这种方法规避了实时延迟问题,但它制造了一个新的瓶颈:为海量用户和物品目录生成知识的巨大计算成本。例如,对于 1000 万用户生成 250 个 token 的用户偏好知识,使用典型的 7B 参数模型大约需要 565 个 GPU 日。
根本原因在于LLM推理的自回归特性,即每个解码步骤按顺序只生成一个 token。当扩展到涉及数十亿实体并需要持续知识更新的工业推荐场景时,这种顺序生成过程变得成本高昂得令人望而却步。
4.2. Methodology
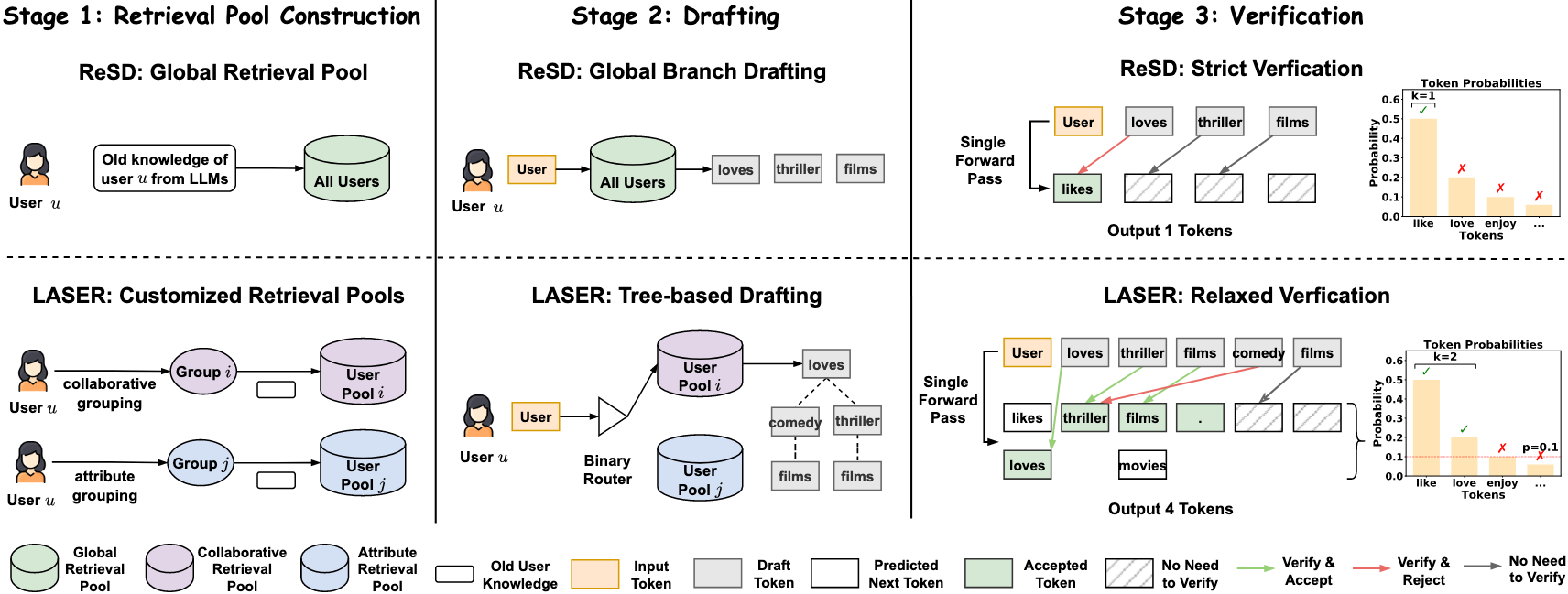
LASER (Lossless Acceleration via Speculative Decoding for LLM-based Recommender Systems) 针对 LLM-based 推荐系统中的知识生成场景,指出两个关键特性:
- 检索效率低:RS 中大量的物品和用户导致检索效率低下。
- 高多样性容忍:推荐系统对 LLM 生成的文本具有较高的多样性容忍度,即多个不同的生成结果可能都具有相同的下游推荐效果。
为此,LASER 提出两个核心组件。
4.2.1. Customized Retrieval Pool
为了解决检索效率问题,LASER 设计了定制化的检索池。该检索池根据用户和物品的特征动态构建,仅包含最相关的 candidates,从而大幅减少检索空间。
具体而言,LASER并非使用单个大规模全局检索池(这对于工业规模的推荐系统来说计算成本过高),而是构建更小、个性化的检索池:
- 基于协同信号的分组:使用来自传统推荐模型(例如 LightGCN)的 embedding 来聚类具有足够交互历史的相似用户或物品。
- 基于属性信号的分组:对于冷启动场景,通过相似属性(类别、子类别等)对实体进行分组。
- 二进制路由器:根据数据可用性智能选择合适的分组方案。
检索到的知识以 Trie 树的结构组织,用于在 drafting 过程中进行高效的前缀匹配。
4.2.2. Relaxed Verification
传统的 Speculative Decoding 方法使用严格的贪婪验证,即仅接受最高概率的 token。LASER 利用了推荐任务的高多样性容忍度,引入了一种放松的接受准则:当某个token经过 target model 验证的概率超过某一阈值,且位于整个 target distribution 的前 $K$ 个 token 中时,即可接受。
4.3. Experiments
4.3.1. 加速能力
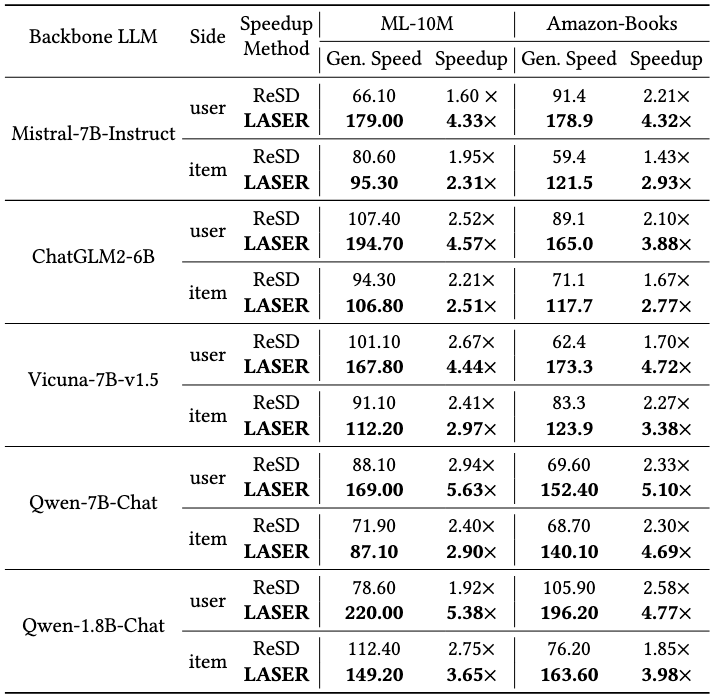
LASER 在不同数据集 (MovieLens-10M、Amazon-Books) 和 LLM 主干模型 (Mistral-7B、ChatGLM2-6B、Vicuna-7B、Qwen-7B) 上,
- 相比于普通自回归解码,始终实现 3-5 倍的加速。
- 相比基于检索的推测解码 (ReSD) 有了显著改进,后者通常只能实现 1.5-2.5 倍的加速。
4.3.2. 下游任务性能
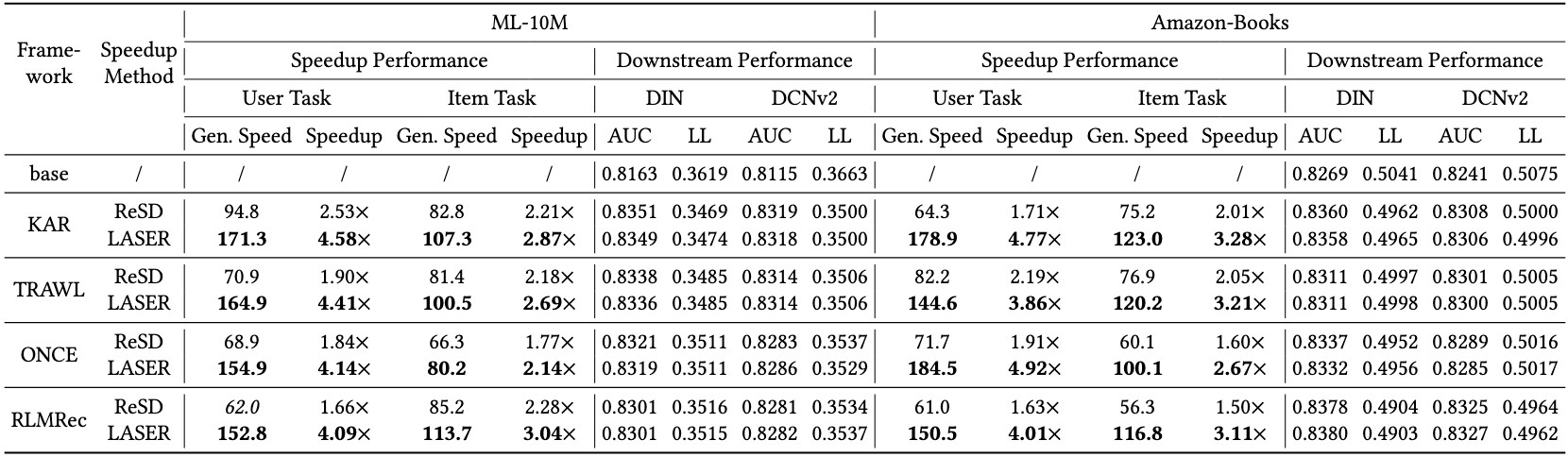
LASER 在下游推荐任务上保持了无损性能。使用 CTR 预测模型在四种不同的基于 LLM 的推荐框架 (KAR、TRAWL、ONCE、RLMRec) 上进行的实验表明,与标准自回归解码生成的知识相比,性能差异几乎可以忽略不计 (AUC/Logloss 差异小于 0.1%)。
5. NEZHA (WWW’26)
📖 NEZHA: A Zero-sacrifice and Hyperspeed Decoding Architecture for Generative Recommendations
🔗 paper: https://arxiv.org/abs/2511.18793
🔗 code: https://github.com/Applied-Machine-LearningLab/WWW2026_NEZHA
5.1. Motivation
NEZHA (A Zero-sacrifice and Hyperspeed Decoding Architecture for Generative Recommendations) 是淘宝团队提出的工业级解决方案。NEZHA 指出现有 SD 方法的两个瓶颈:
- Drafting:现有方法依赖外部 draft model(如更小的 LLM 或检索 model),需要额外训练和维护成本。
- Verification:现有方法仍需调用原始大模型来验证 drafted tokens,无法完全避免耗时的 LLM 解码步骤。
5.2. Methodology
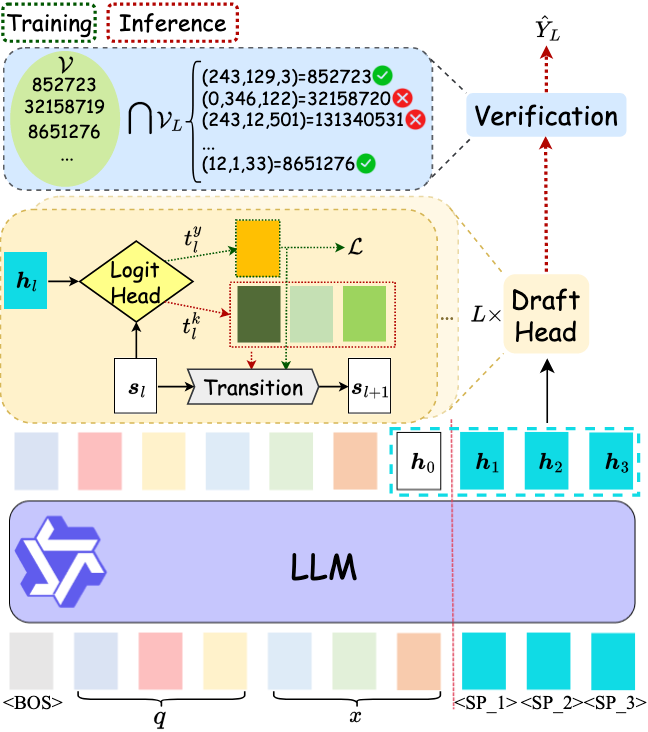
NEZHA 提出两个核心创新:灵活的自草稿生成和高效的无模型验证。
5.2.1. Nimble Self-Drafting
NEZHA 采用自 drafting 架构,将轻量级的自回归 draft head 直接集成到主模型中,使模型能够高效地自行预测 next item,无需训练和 serving 额外的模型。
具体而言,NEZHA 修改输入 prompt,为每个训练实例 ${(q, x), y}$ 添加 $L$ 个特殊占位符 token:
\[\begin{equation} [\text{<BOS>}, q, t_1^1, t_2^1, t_3^1, \dots, t_1^N, t_2^N, t_3^N, \text{<SP\_1>}, \dots, \text{<SP\_L>}, \text{<EOS>}] \end{equation}\]这些占位符使 LLM 能够在单次 forward pass 中预计算所有未来 token 位置的 hidden states。
Draft head 定义为:
\[\begin{equation} \begin{aligned} s_1 &= h_0 \\ p_l &= \text{logit\_head}_l(h_l, s_l) \\ s_{l+1} &= \text{Transition}_l(s_l, e_l) \end{aligned} \end{equation}\]其中 $h_0$ 是 LLM prefill 得到的 hidden state,$s_l$ 是演化的 context state,$e_l$ 是所选 token 的 embedding。
5.2.2. Efficient Model-Free Verification
为了解决 verification 瓶颈,NEZHA 提出基于 hash set 的 model-free verification 方法。该方法将 drafted item 与预计算的所有有效物品 ID 的 hash set 进行比对,无需调用 LLM。
具体而言,验证过程为:
\[\begin{equation} \text{Valid}(s) = \mathbb{I}(s \in \mathcal{V}) \end{equation}\]其中 $\mathcal{V}$ 是所有有效语义 ID 的 hash set。
这种方法可以有效检测模型的 hallucination,即生成了无效的语义 ID,同时避免了 LLM 调用。
5.2.3. NEZHA 的训练和推理流程

NEZHA Training Process |

NEZHA Inference Process |
5.3. Experiments

NEZHA 在多个维度上展示了显著的性能提升。在公共数据集 Yelp、Amazon-Beauty 和 Amazon-Games 上,使用 Llama-1B 和 QWen3-0.8B 作为骨干模型,NEZHA 在保持或提高推荐质量的同时,生成延迟实现了约 10 倍的加速。
6. SpecGR (AAAI’26)
📖 Inductive Generative Recommendation via Retrieval-based Speculation
🔗 paper: https://arxiv.org/abs/2410.02939
🔗 code: https://github.com/Jamesding000/SpecGR
6.1. Motivation
SpecGR (Speculative Generative Recommendation) 针对生成式推荐的一个核心局限:归纳式推荐能力不足。传统 GR 模型只能在训练时见过的物品中生成推荐,无法推荐新物品。
SpecGR 将 SD 的 draft-verify 框架扩展为:使用具有归纳能力的 drafter 提出 candidate items(包括新物品),然后用 GR model 作为 verifier 来接受或拒绝这些候选。
在这种设置下,drafter 充当一个检索引擎,能够处理样本内和未见过的物品。GR model 作为验证器,通过计算它生成这些物品语义 ID 序列的可能性来评估这些候选物品。
6.2. Methodology
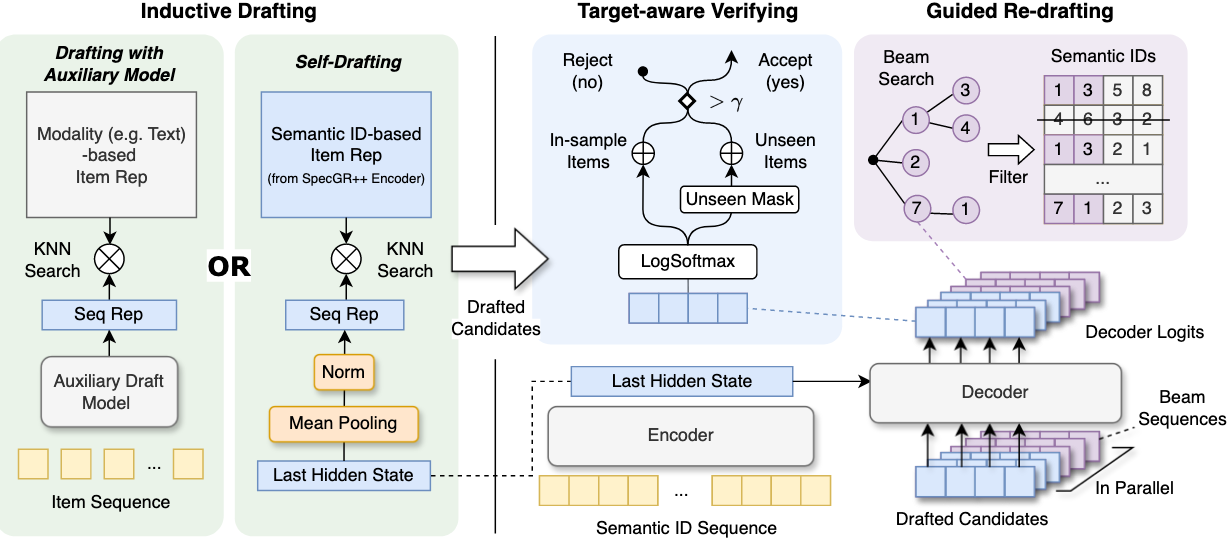
SpecGR 包含四个核心组件。
6.2.1. Inductive Drafting
给定输入物品序列 $X$,drafter $D(\cdot)$ 提出 $\delta$ 个候选物品:
\[\begin{equation} \mathcal{Q} = D(X) \end{equation}\]这些候选物品从一个包含训练期间已见物品和新物品的池中检索。
6.2.2. Target-Aware Verifying
GR模型作为查询似然模型 (Query-Likelihood Model, QLM) 来评估候选物品,它计算一个验证分数 $V(x_t, X)$,即给定序列 $X$ 时候选物品 $x_t$ 的对数似然。
对于模型未曾见过的项目,它通常难以处理语义ID的最后一个标记(识别标记)。为了解决这个问题,SpecGR 排除了最后一个标记,来修改未见项目的评分:
\[V(x_t, X) = \begin{cases} \frac{1}{l} \sum_{i=1}^{l} \log P(c_i \mid c_{<i}, X),& \text{if } x_t\in\mathcal{I}\\ \frac{1}{l-1} \sum_{i=1}^{l-1} \log P(c_i \mid c_{<i}, X),& \text{if } x_t\in\mathcal{I^{\ast}}\setminus \mathcal{I} \end{cases}\]6.2.3. Guided Re-Drafting
如果初始 drafting 未能产生足够数量的高质量候选物品(少于目标数量 $K$),GR 模型将重新启动一个部分解码过程,使用束搜索来生成语义ID的前缀。
然后,这些前缀 $B_j$ 被送回给 drafter,仅生成与这些前缀匹配的新候选物品。这确保了 drafter 可以专注于 GR 模型已经发现有前景的物品子空间,从而提高了下一个验证周期的效率。
6.2.4. Adaptive Exiting
SpecGR 迭代地进行起草和验证步骤,直到最终有 $K$ 个物品被接受。如果提前找到了 $K$ 个物品,,该过程就会终止,从而节省计算时间。这使得系统比标准 beam search 更高效,因为标准 beam search 必须始终为每个候选项目解码到完整的长度 $l$。
6.3. SpecGR++: Parameter-Efficient Self-Drafting
虽然使用辅助模型(如 UniSRec)作为 drafter 更具灵活性,但它需要维护两个独立的模型。为了解决这个问题,作者开发了SpecGR++,它使用 GR 模型自身的内部编码器作为 drafter。
为了使编码器能够进行高质量的检索,作者引入了一个两阶段的训练范式:
- 对比预训练:模型使用多任务进行联合训练。除了标准的 next-token prediction外,还使用对比学习来确保编码器的 hidden state 能够有效地将相似的物品和序列聚类在一起。
- 排序学习微调: 使用交叉熵损失进一步优化编码器,以提高其区分正样本物品和大量负样本物品的能力。
6.4. Experiments
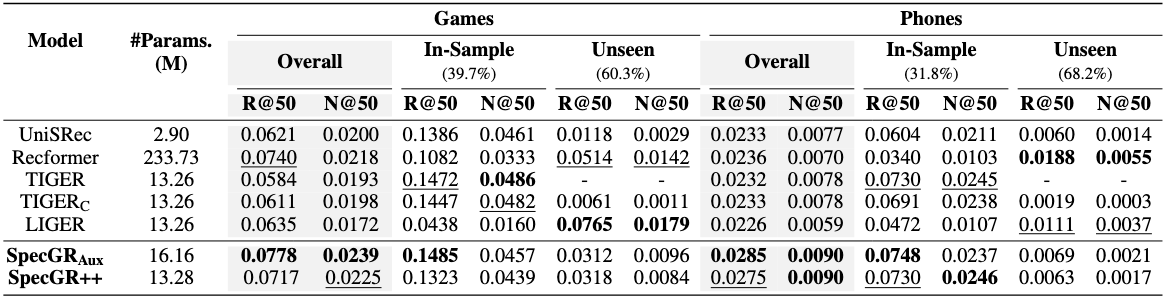
实验结果指出,SpecGR 能够为 GR 模型赋予归纳能力。TIGER 等 GR 模型在未见物品上的性能接近于零,SpecGR 显著改善了这些指标。更重要的是,这种归纳能力的提升并未以牺牲样本内性能为代价,模型对于训练期间已见的项目仍然保持高度准确。
7. 总结与展望
7.1. 技术趋势
- 从外部 draft 到 self-draft:NEZHA 和 SpecGR++ 都采用了自drafting 架构,减少了额外模型的维护成本。
- 从严格验证到松弛验证:AtSpeed、LASER 和 NEZHA 都提出了不同形式的松弛验证策略,利用推荐系统的特性来提高接受率。
- 从 transductive 到 inductive:SpecGR 首次将 SD 框架用于解决归纳式推荐问题,扩展了 GR 的应用范围。
7.2. 未来方向
- 更高效的 draft 架构:探索更轻量的 draft head 设计,进一步降低 drafting 开销。
- 自适应验证策略:根据场景动态调整验证阈值,平衡加速比和推荐质量。
- 多模态 GR 加速:将 SD 技术扩展到多模态生成式推荐场景。
- 端到端优化:将 SD 与 KV-Cache、量化等其他加速技术结合,实现端到端的推理优化。
Appendix
Apd.1. Proof of Theorem 1.
首先,我们证明预测解码的每一步结束后,当前前缀的分布与目标模型自回归分布相同,即单步预测解码可以修正分布。
Lemma 1(单步接受-拒绝机制的正确性) 设当前前缀为 $s=x_{\lt t}$。执行如下过程:
-
从 draft 分布采样:
\[\begin{equation} Y \sim q(\cdot \mid s) \end{equation}\] -
以概率
\[\begin{equation} \alpha(Y) = \min\left(1, \frac{p(Y \mid s)}{q(Y \mid s)}\right) \end{equation}\]接受 $Y$
-
若拒绝,则从残差分布采样一个新token:
\[\begin{equation} Z\sim r(v \mid s) = \frac{\max(p(v \mid s) - q(v \mid s),0)}{\sum_u \max(p(u \mid s) - q(u \mid s),0)} \end{equation}\]
记最终输出为 $T$,则有:
\[\begin{equation} T \sim p(\cdot \mid s) \end{equation}\]证明. 对任意 token $v$,有:
\[\begin{equation} \Pr(T = v) = \Pr(Y = v) + \Pr(Z = v) \end{equation}\]其中,第一项表示接受 draft token $Y$ 的概率:
\[\begin{equation} \begin{aligned} \Pr(Y = v) &= q(v \mid s)\,\alpha(v)\\ &= q(v \mid s)\min\left(1, \frac{p(v \mid s)}{q(v \mid s)}\right)\\ &= \min\bigl(q(v \mid s), p(v \mid s)\bigr) \end{aligned} \end{equation}\]因此,拒绝 draft token 的总概率为:
\[\begin{equation} \begin{aligned} \beta &= 1 - \sum_u \Pr(Y = u)\\ &= 1 - \sum_u \min(q(u \mid s), p(u \mid s)) \end{aligned} \end{equation}\]第二项表示拒绝 draft token 且输出为 $v$ 的概率:
\[\begin{equation} \begin{aligned} \Pr(Z = v) &= \beta \cdot r(v \mid s)\\ &= \beta\cdot \frac{\max(p(v \mid s) - q(v \mid s),0)}{\sum_u \max(p(u \mid s) - q(u \mid s),0)} \end{aligned} \end{equation}\]注意到上式的分母可以做如下等价变形:
\[\begin{equation} \begin{aligned} \sum_u \max(p(u \mid s) - q(u \mid s),0) &= 1 - \sum_u \min(p(u \mid s), q(u \mid s))\\ &= \beta \end{aligned} \end{equation}\]因此:
\[\begin{equation} \Pr(Z = v) =\max(p(v \mid s) - q(v \mid s),0) \end{equation}\]从而:
\[\begin{equation} \Pr(T = v) = \min(q(v \mid s), p(v \mid s)) + \max(p(v \mid s) - q(v \mid s),0) \end{equation}\]利用恒等式:
\[\begin{equation} \min(a,b) + \max(a-b,0) = a \end{equation}\]得到:
\[\begin{equation} \Pr(T = v) = p(v \mid s) \end{equation}\]Lemma 1 得证。
Theorem 1(Speculative Decoding 的分布一致性) 设 $X_1, X_2, \dots$ 为通过 Speculative Decoding 生成的序列,则对任意序列 $x_{1:n} $,有:
\[\begin{equation} \Pr(X_{1:n} = x_{1:n}) = \prod_{t=1}^n p(x_t \mid x_{<t}) \end{equation}\]即 Speculative Decoding 的输出分布与使用 target model 进行标准自回归采样分布完全一致。
证明. 只需证明对任意位置 $t$,有:
\[\begin{equation} \Pr(X_t = x_t \mid X_{<t} = x_{<t}) = p(x_t \mid x_{<t}) \end{equation}\]考虑任意已生成前缀 $x_{<t}$。在 Speculative Decoding 中,下一个输出 token 的生成过程为:
- 从 $q(\cdot \mid x_{<t})$ 采样 draft token;
- 使用接受-拒绝机制进行校正;
- 若拒绝,则从残差分布中采样一个新token。
该过程与Lemma 1 完全一致,因此有:
\[\begin{equation} \Pr(X_t = x_t \mid X_{<t} = x_{<t}) = p(x_t \mid x_{<t}) \end{equation}\]根据概率链式法则: \(\begin{equation} \Pr(X_{1:n} = x_{1:n}) = \prod_{t=1}^n \Pr(X_t = x_t \mid X_{<t} = x_{<t}) = \prod_{t=1}^n p(x_t \mid x_{<t}) \end{equation}\)
因此,Speculative Decoding 的输出分布与 target 模型自回归采样完全一致。
Theorem 1 证毕。